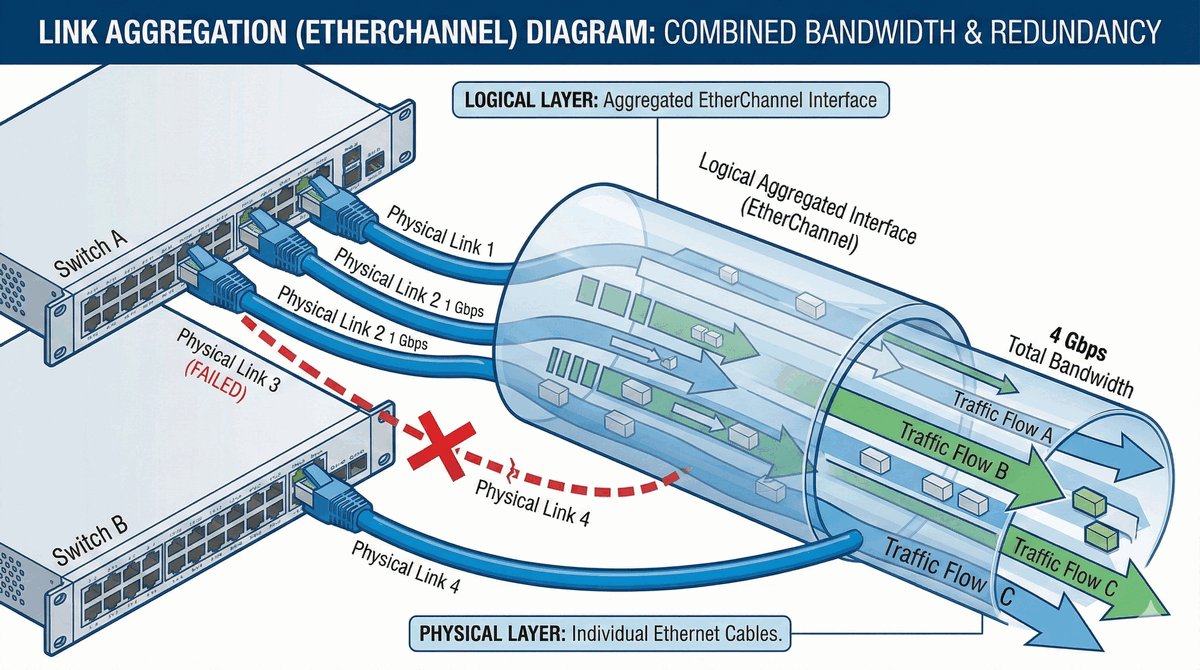
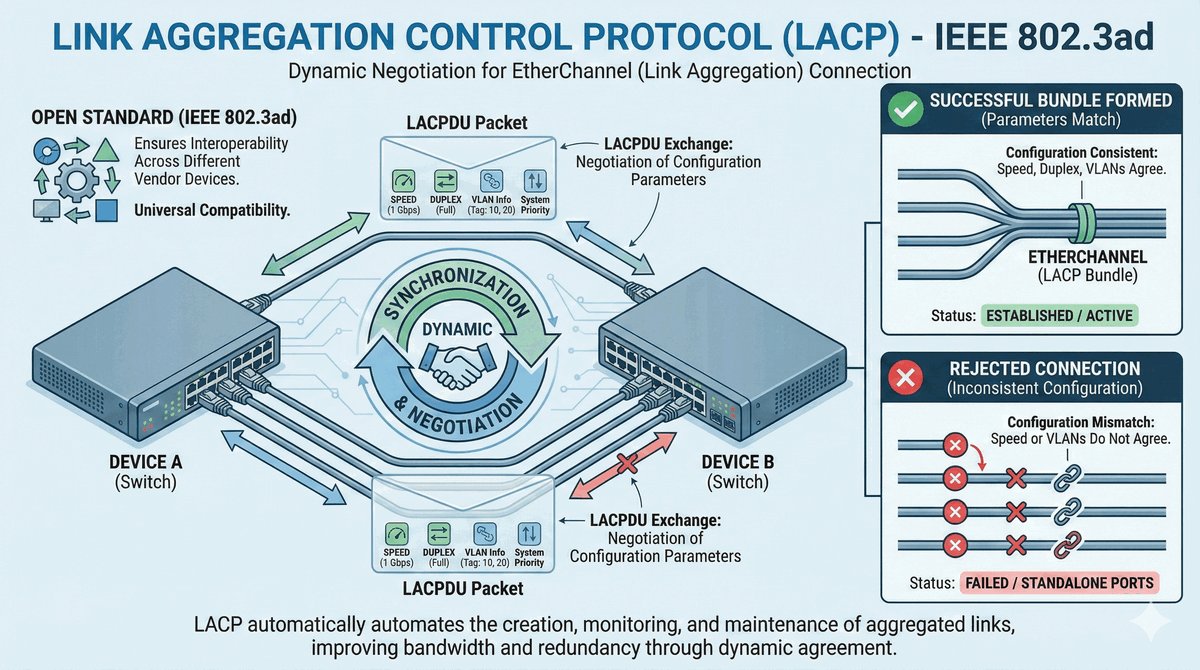
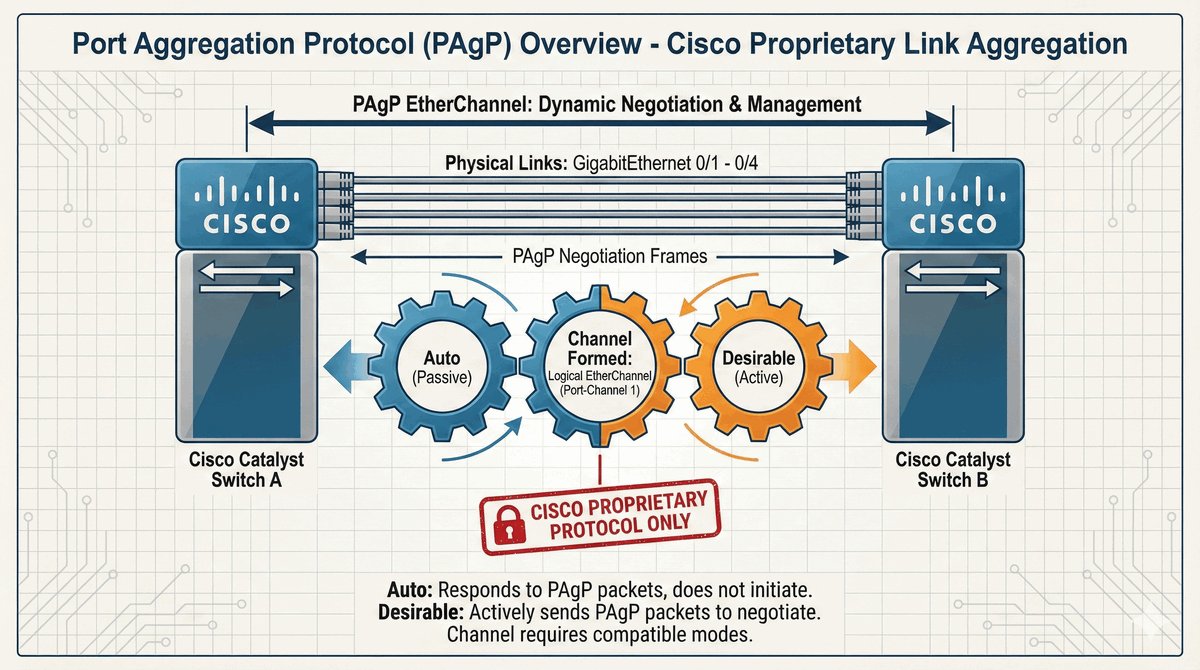
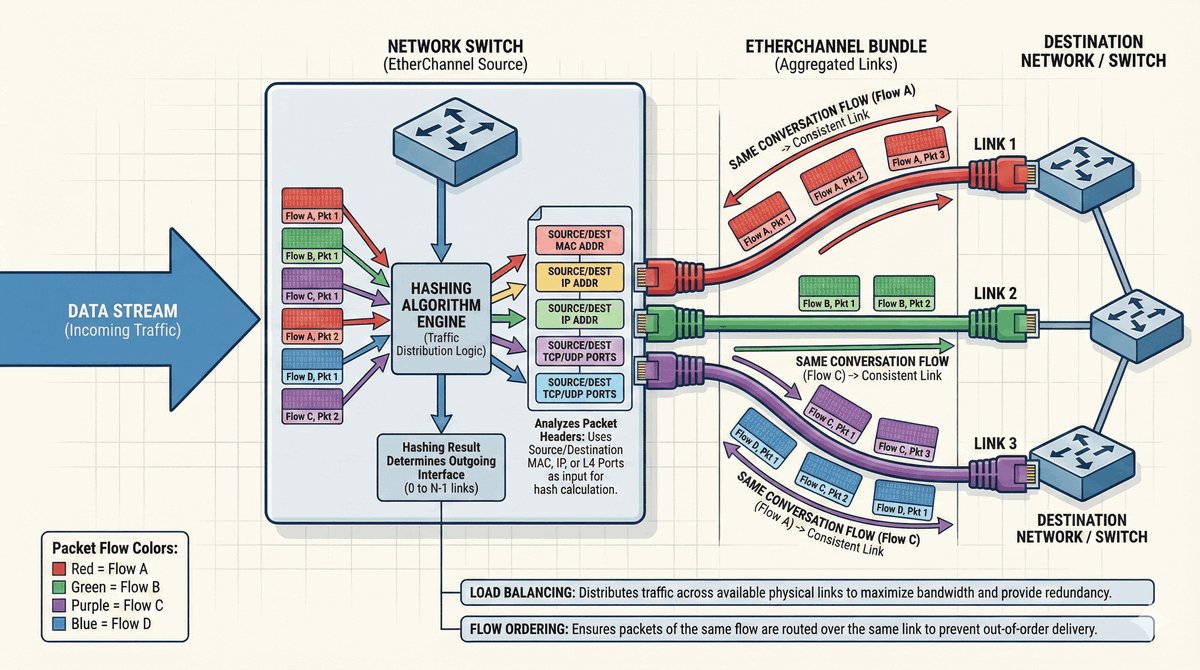
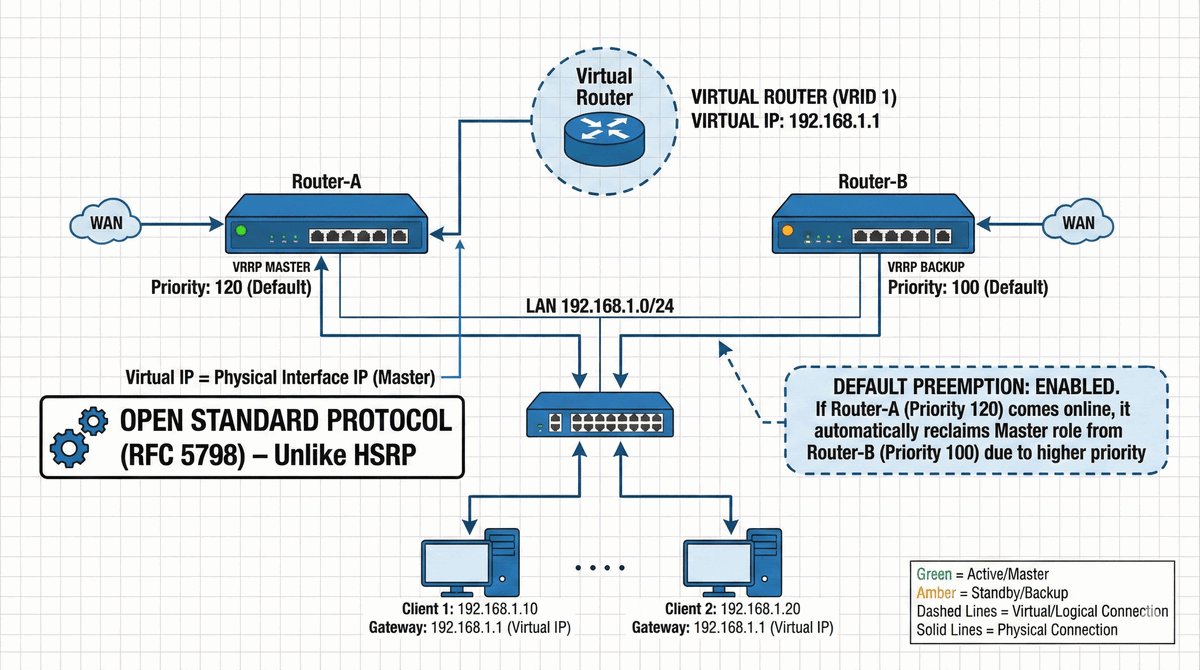
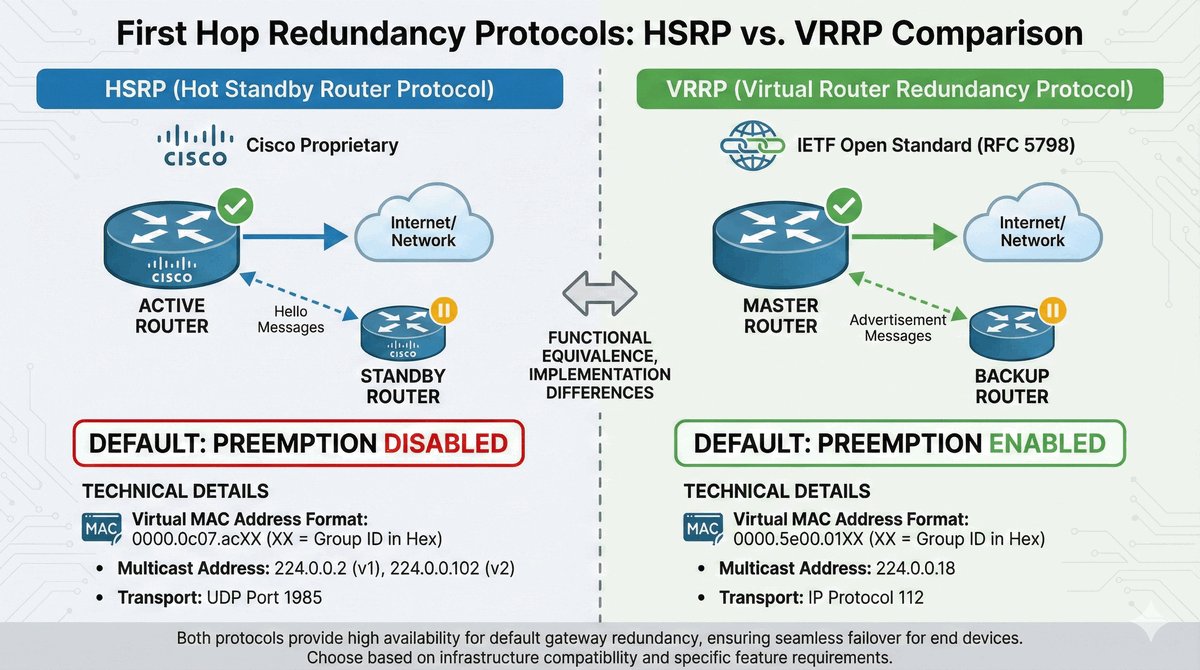
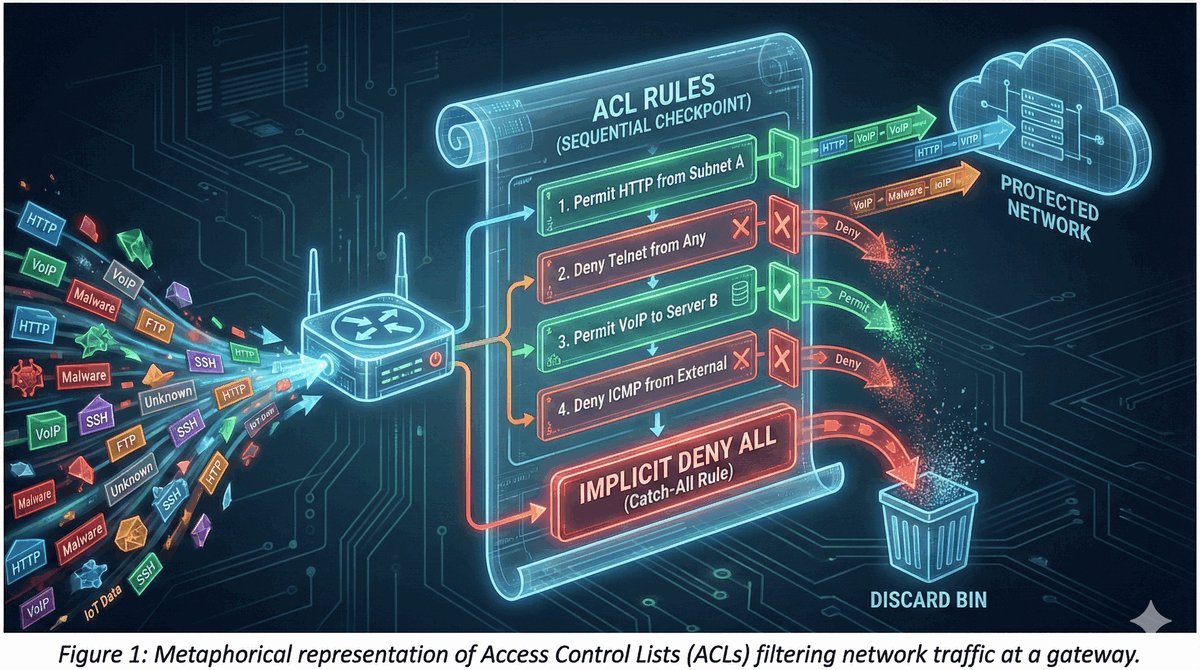
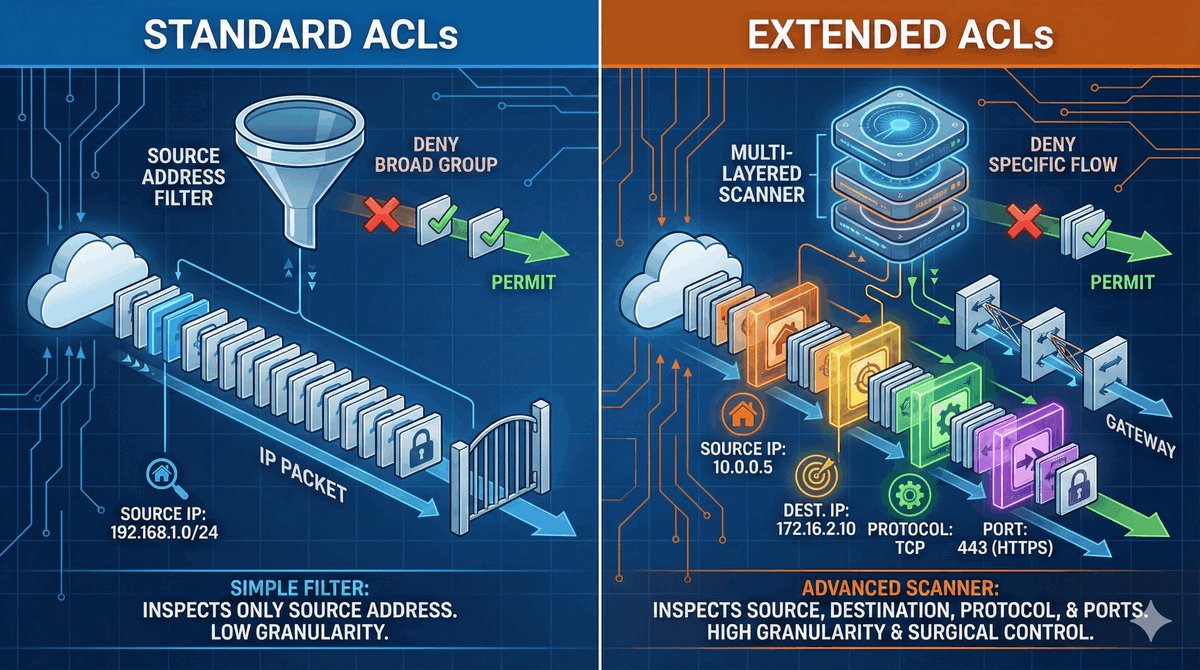
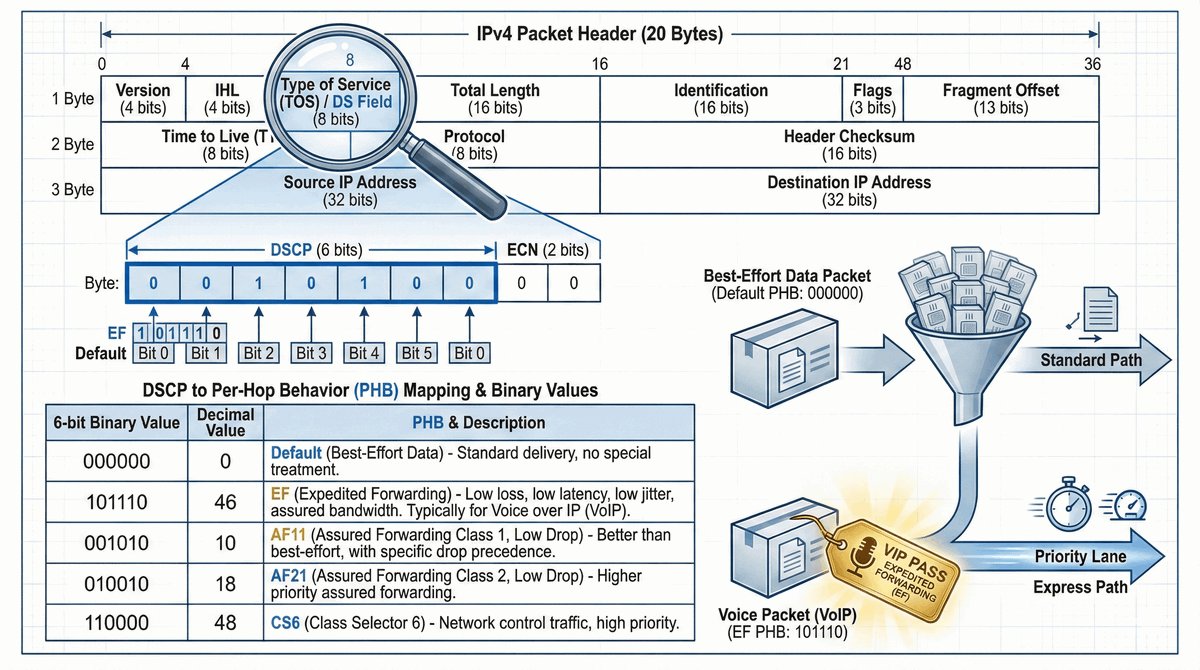
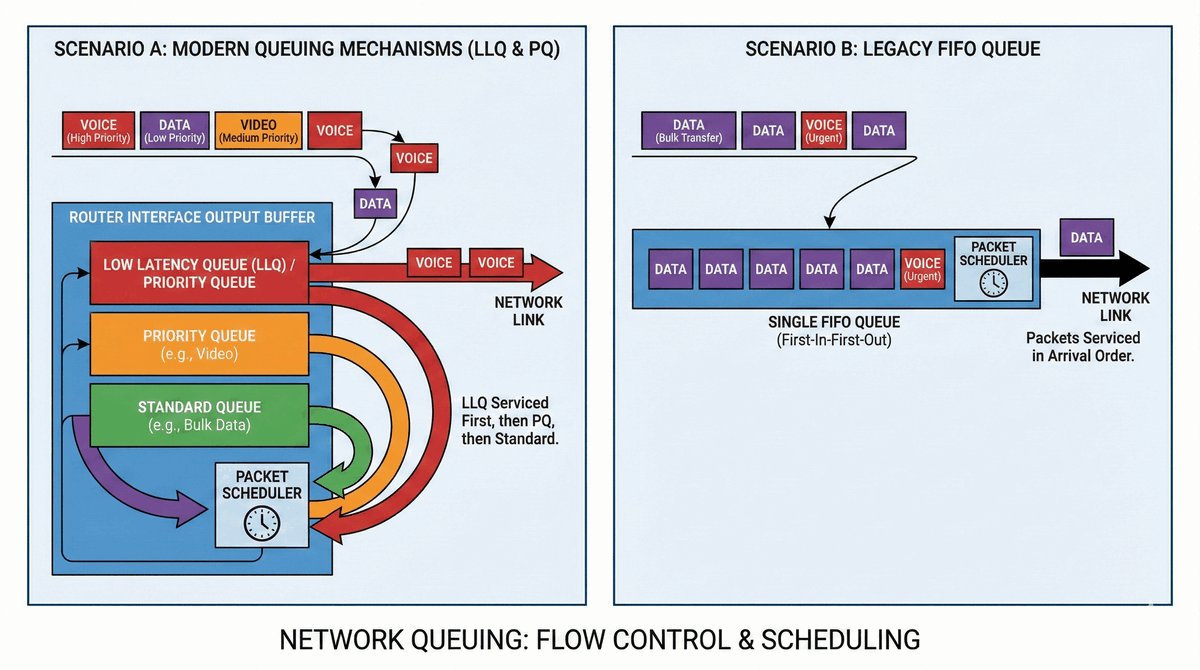
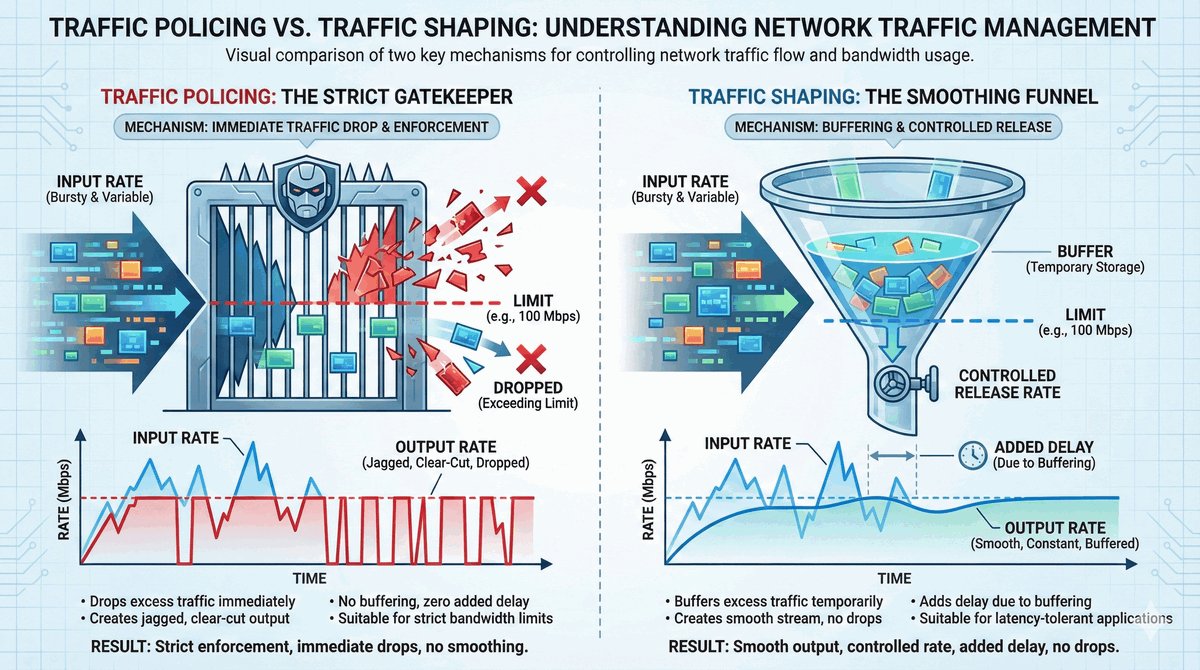
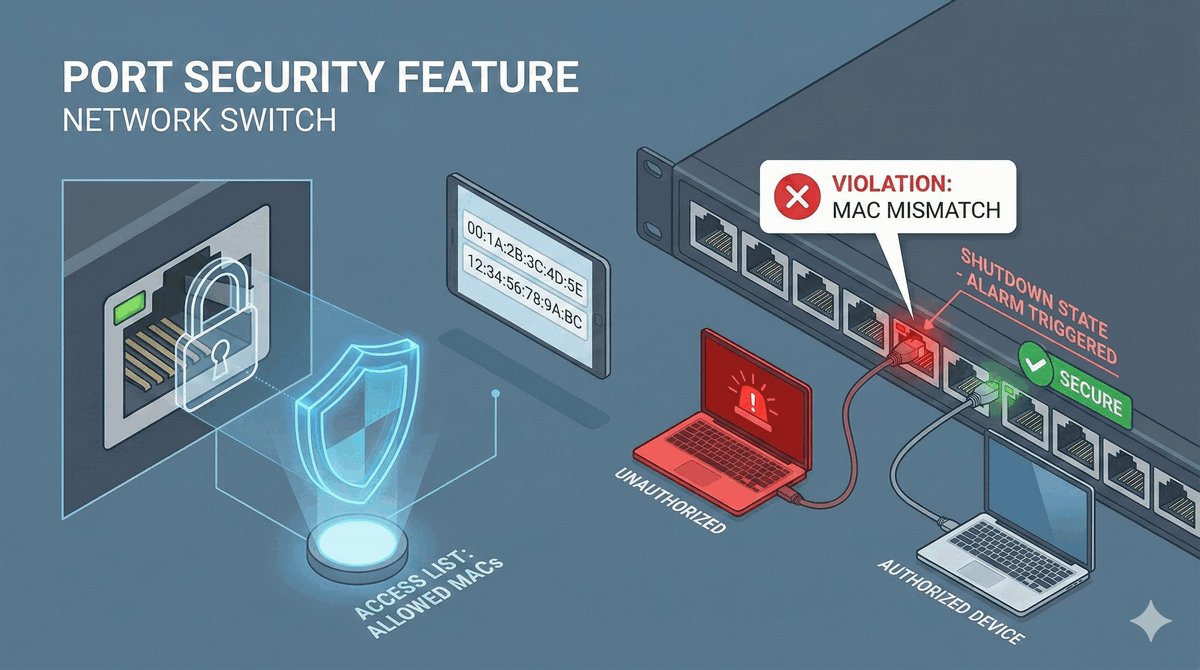
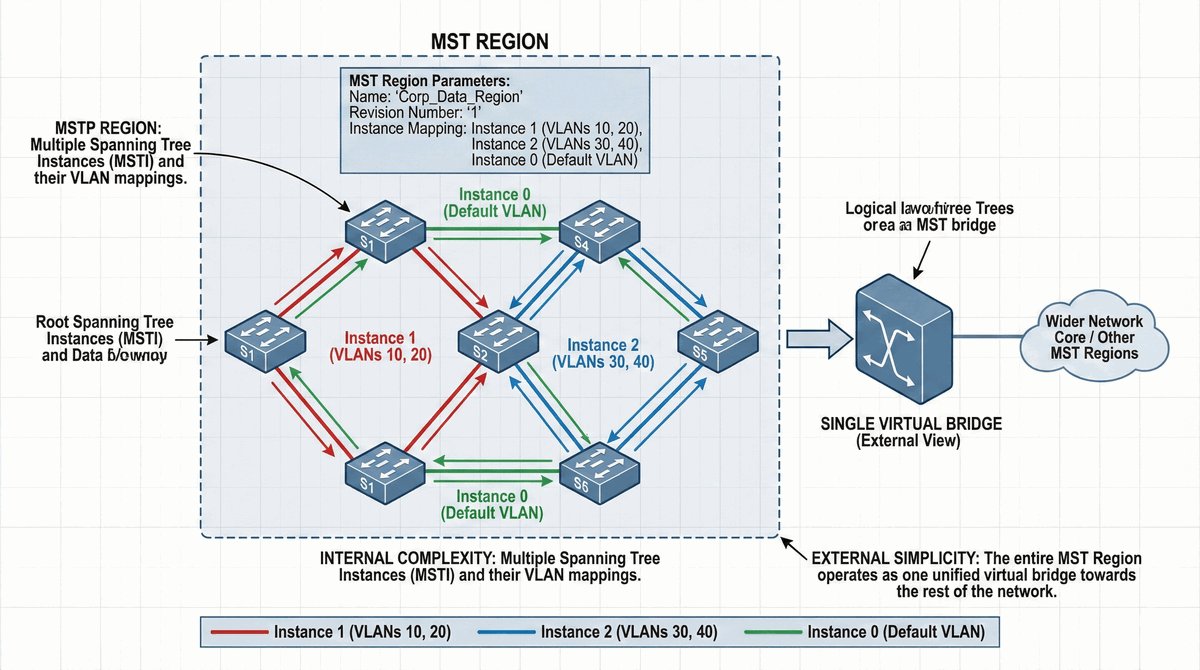
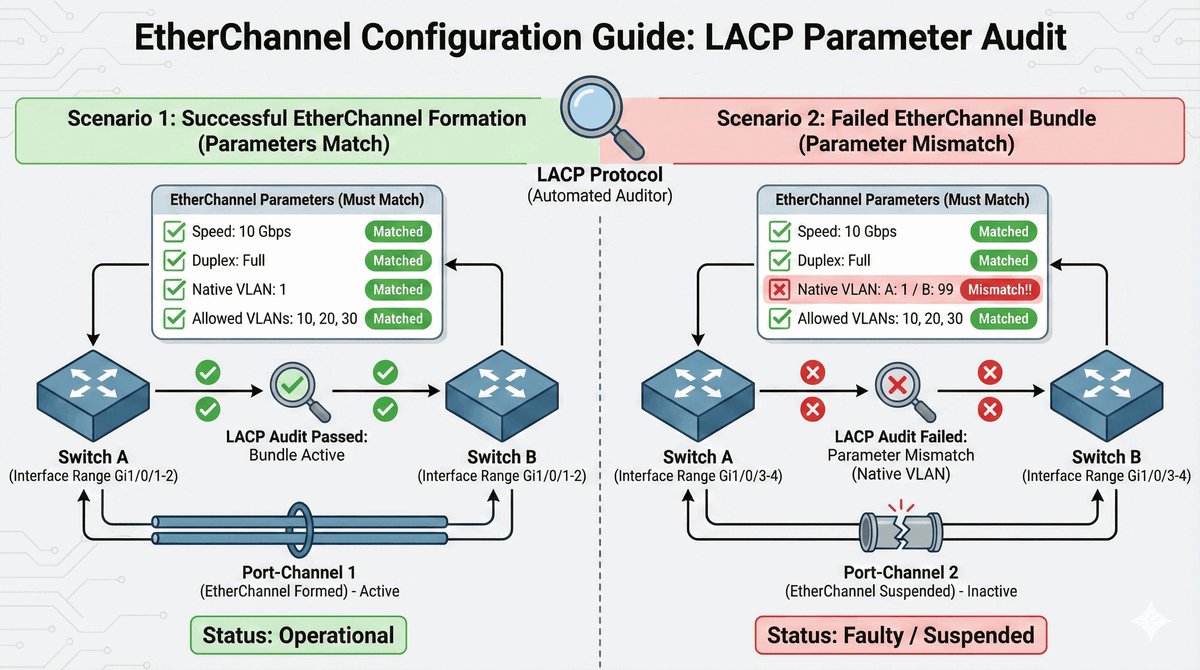
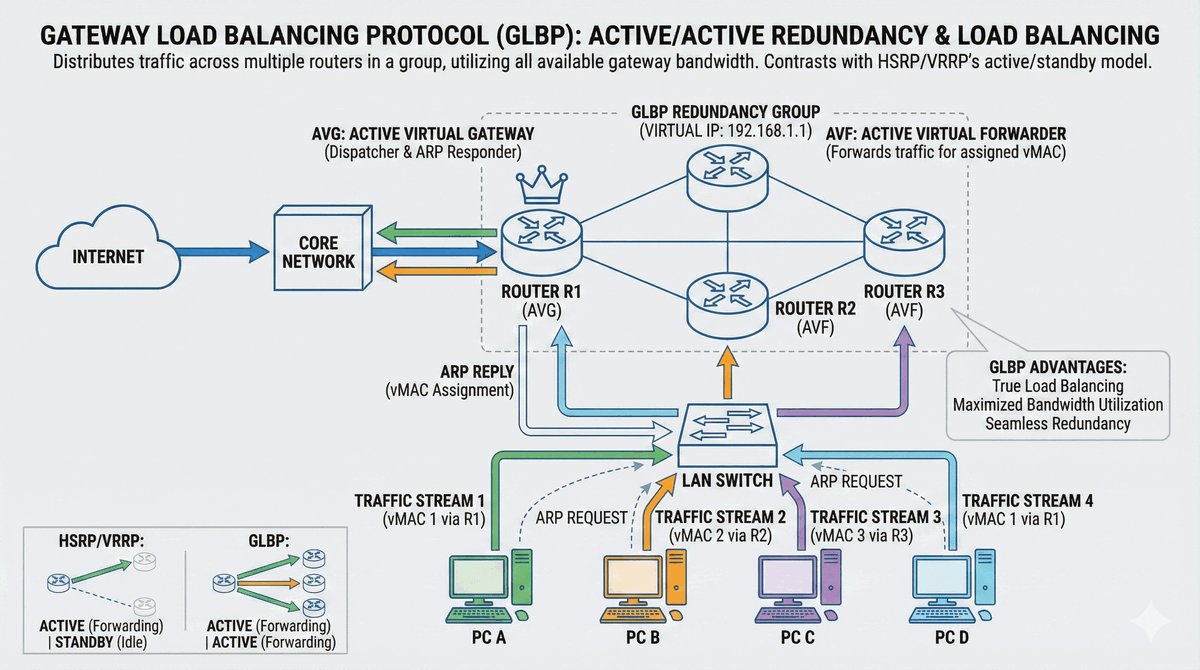
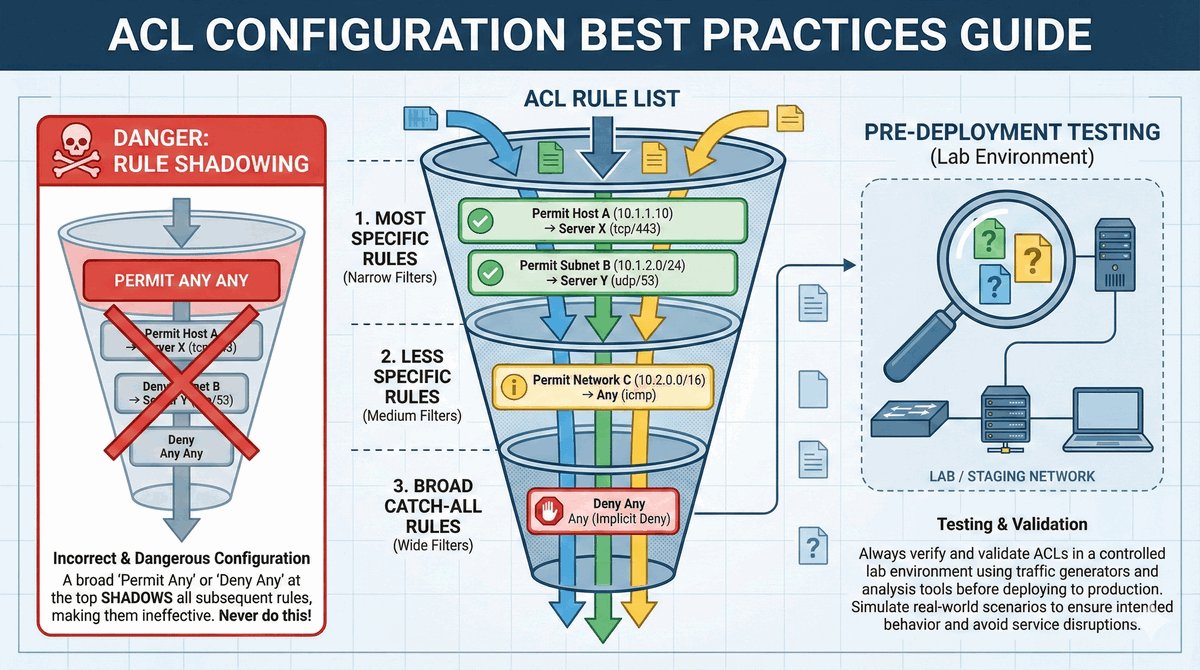
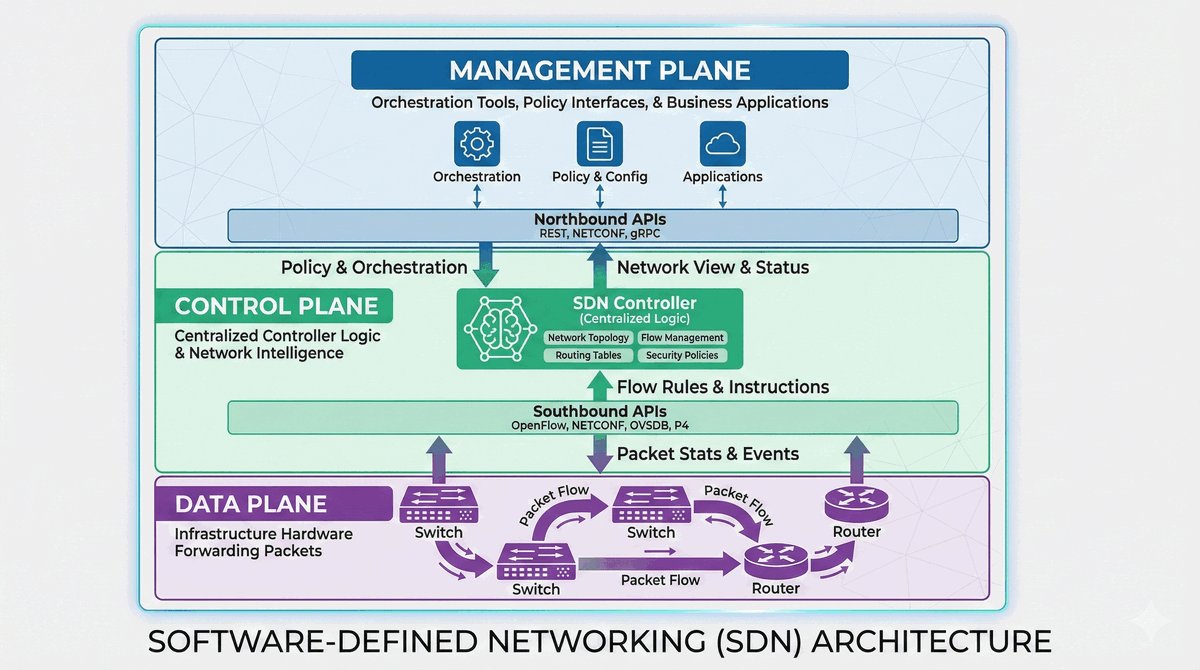
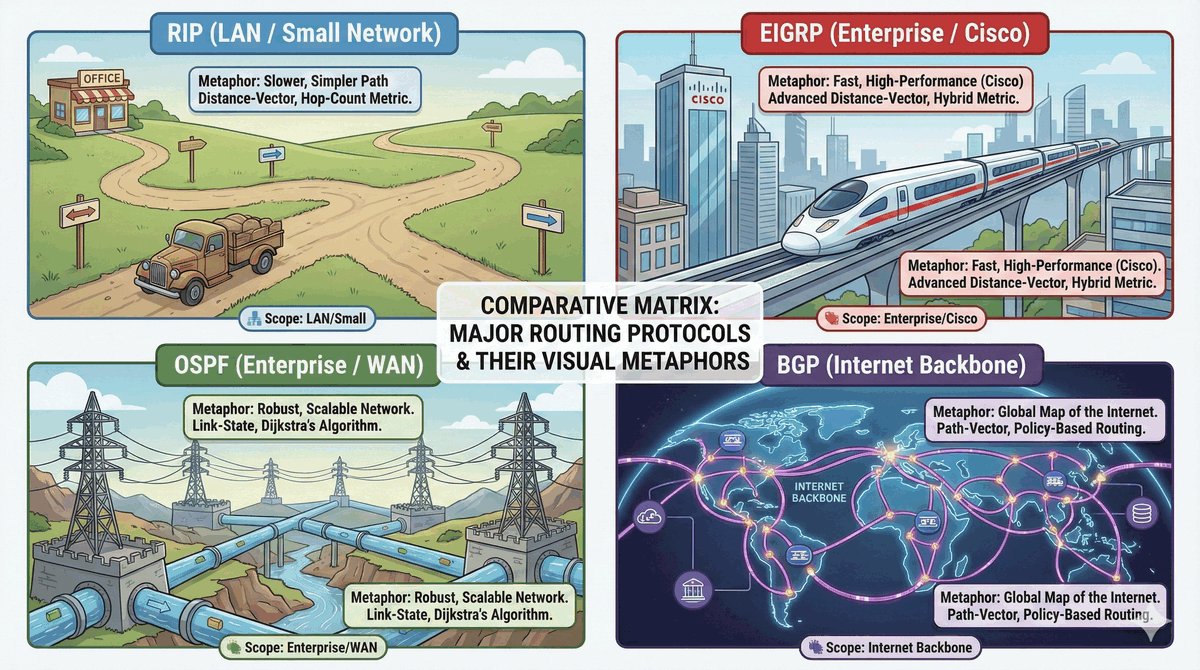
Przepustka VIP dla urządzeń końcowych
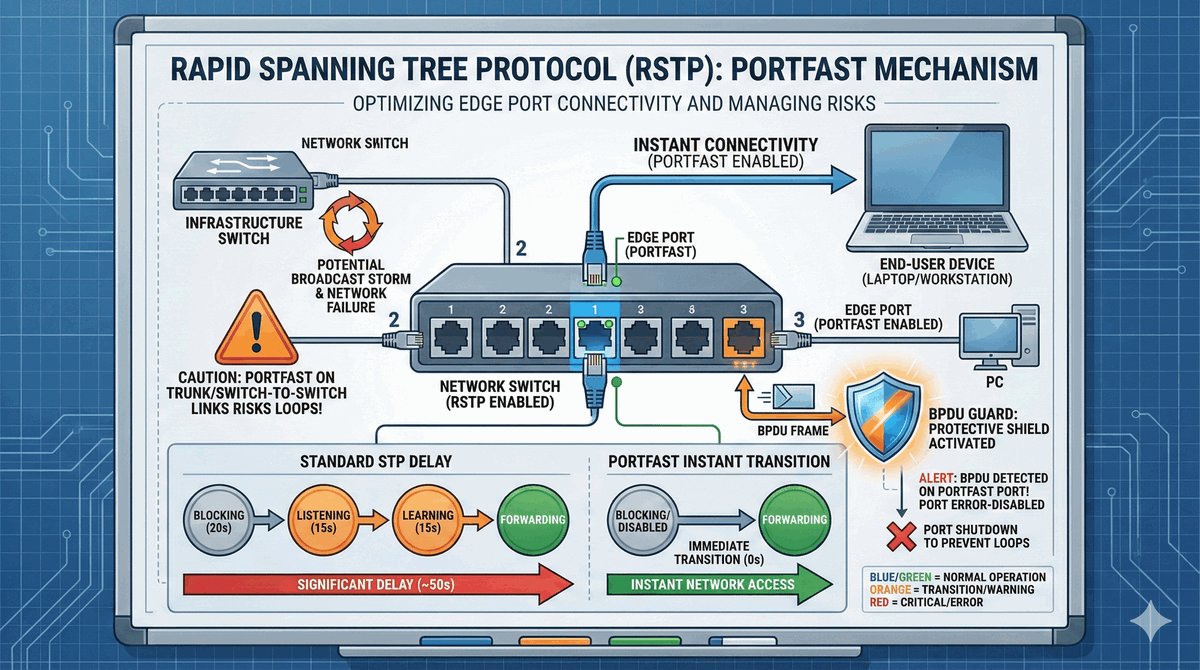
Nikt nie lubi czekać 30 sekund na internet po wpięciu kabla. Funkcja PortFast to „przepustka VIP" dla urządzeń końcowych (PC, drukarki). Pozwala portowi przeskoczyć wszystkie nudne etapy nasłuchiwania STP i od razu przejść do pracy.
Ale uwaga: ta funkcja jest tylko dla „cywilów". Jeśli włączysz ją na porcie, do którego podłączysz inny switch, ryzykujesz natychmiastową pętlę. Dlatego zawsze stosujemy duet: PortFast plus BPDU Guard. Ten drugi to strażnik, który natychmiast wyłączy port, jeśli wykryje na nim inny switch, chroniąc naszą sieć przed błędem nowicjusza.