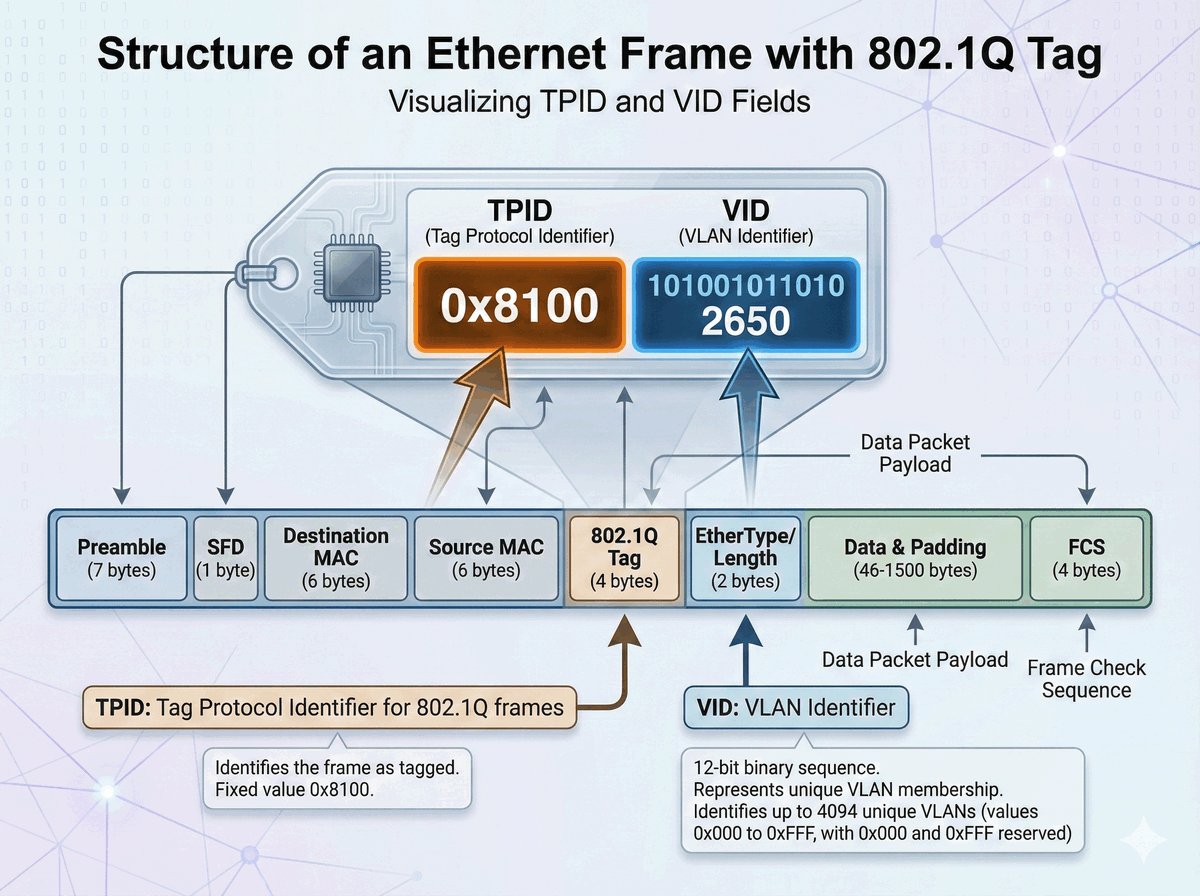
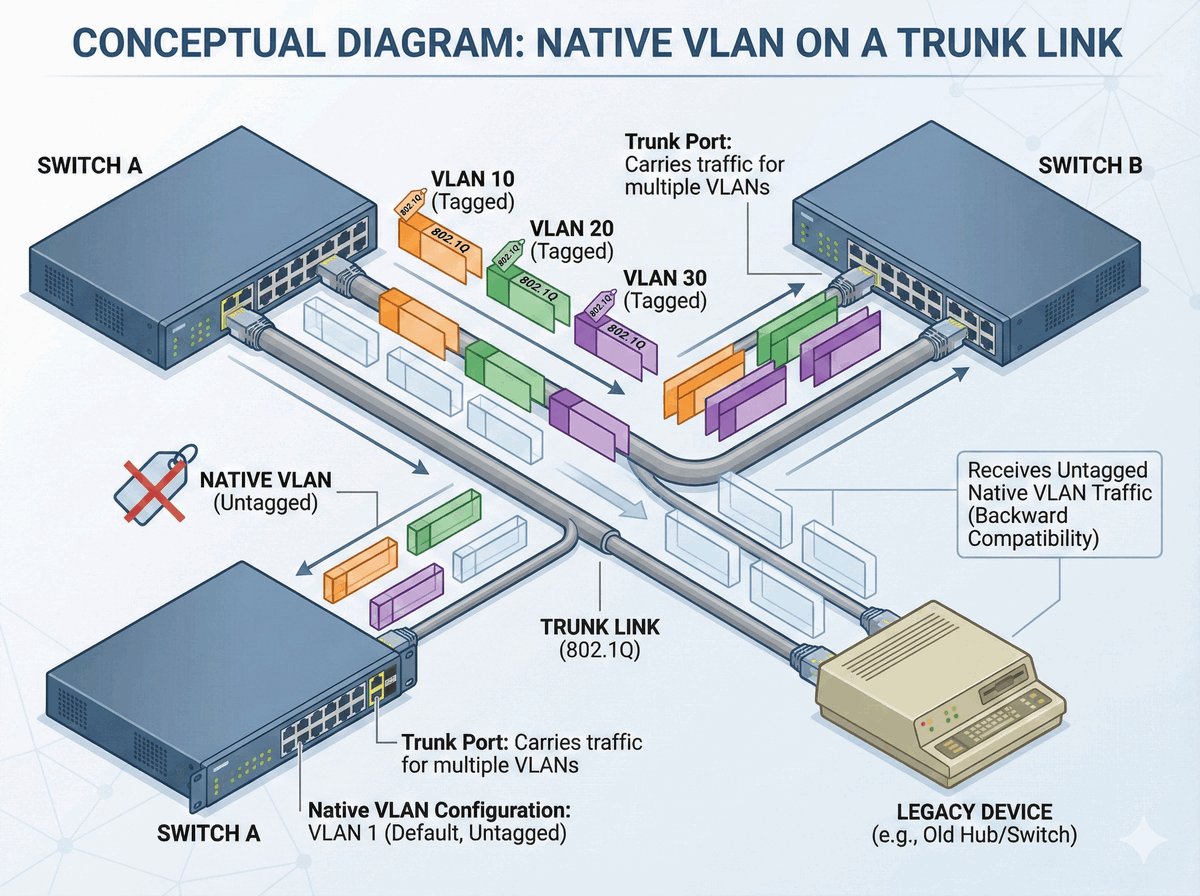
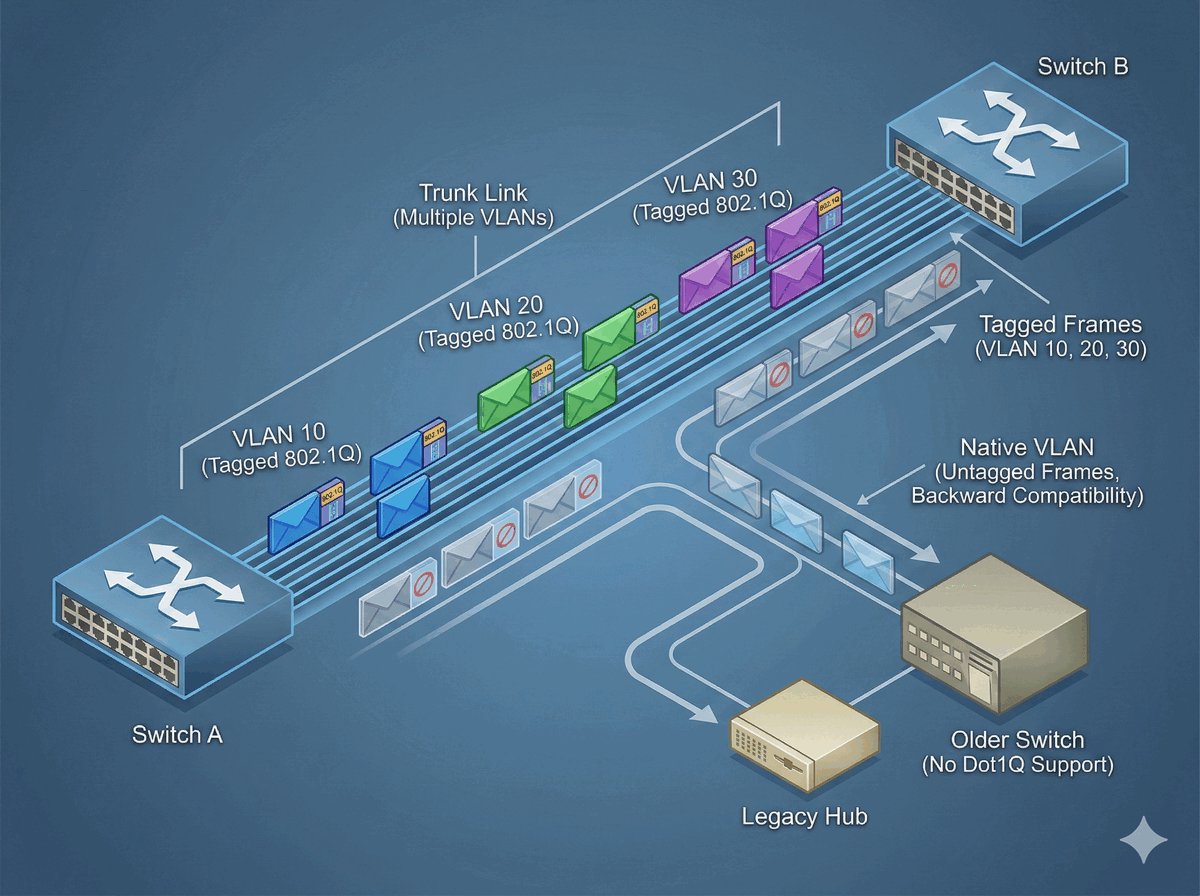
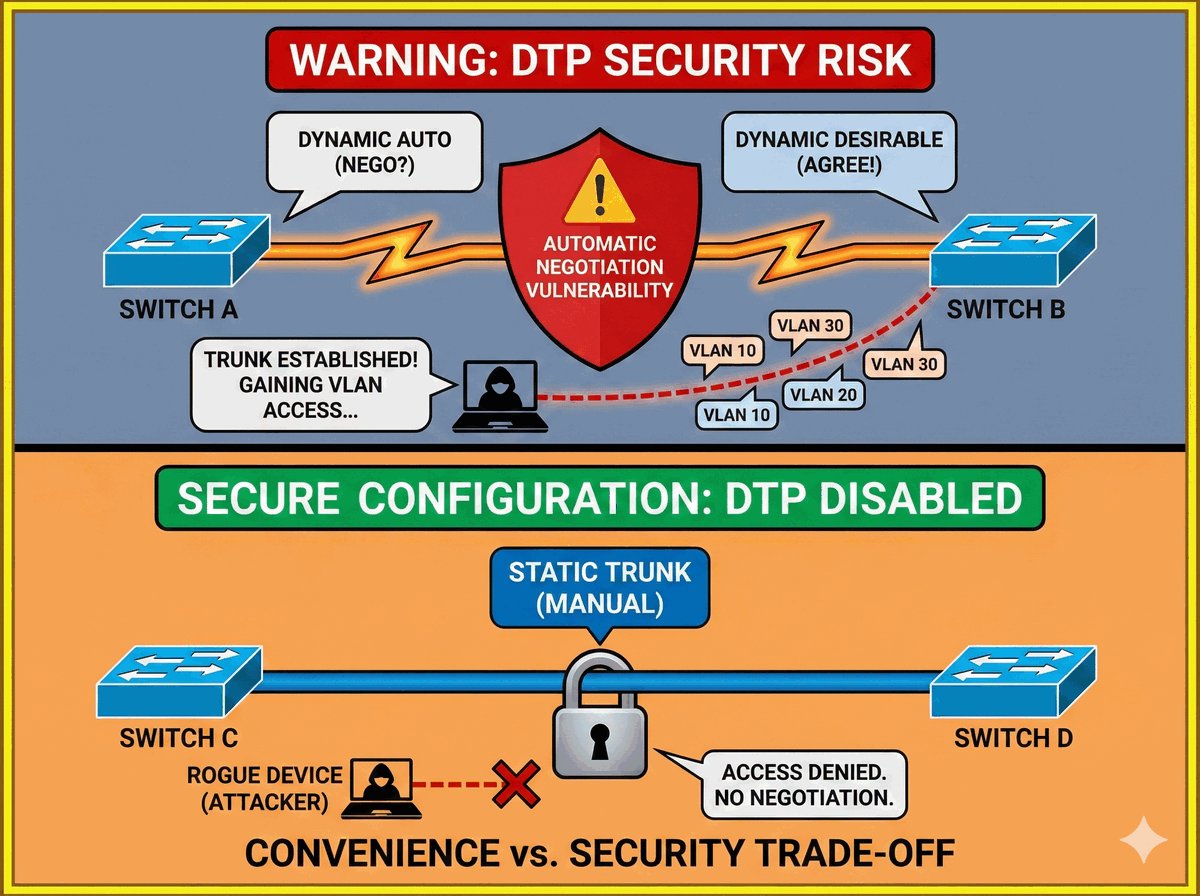
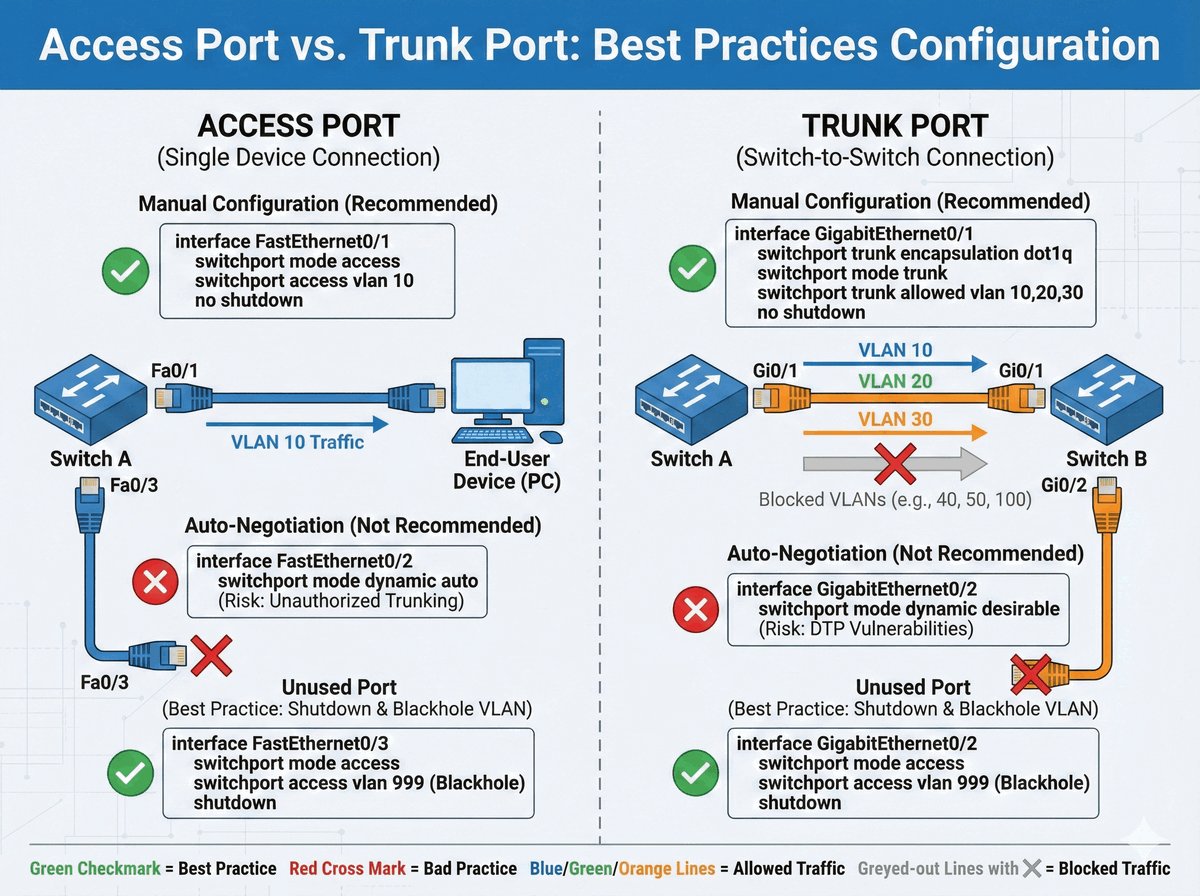
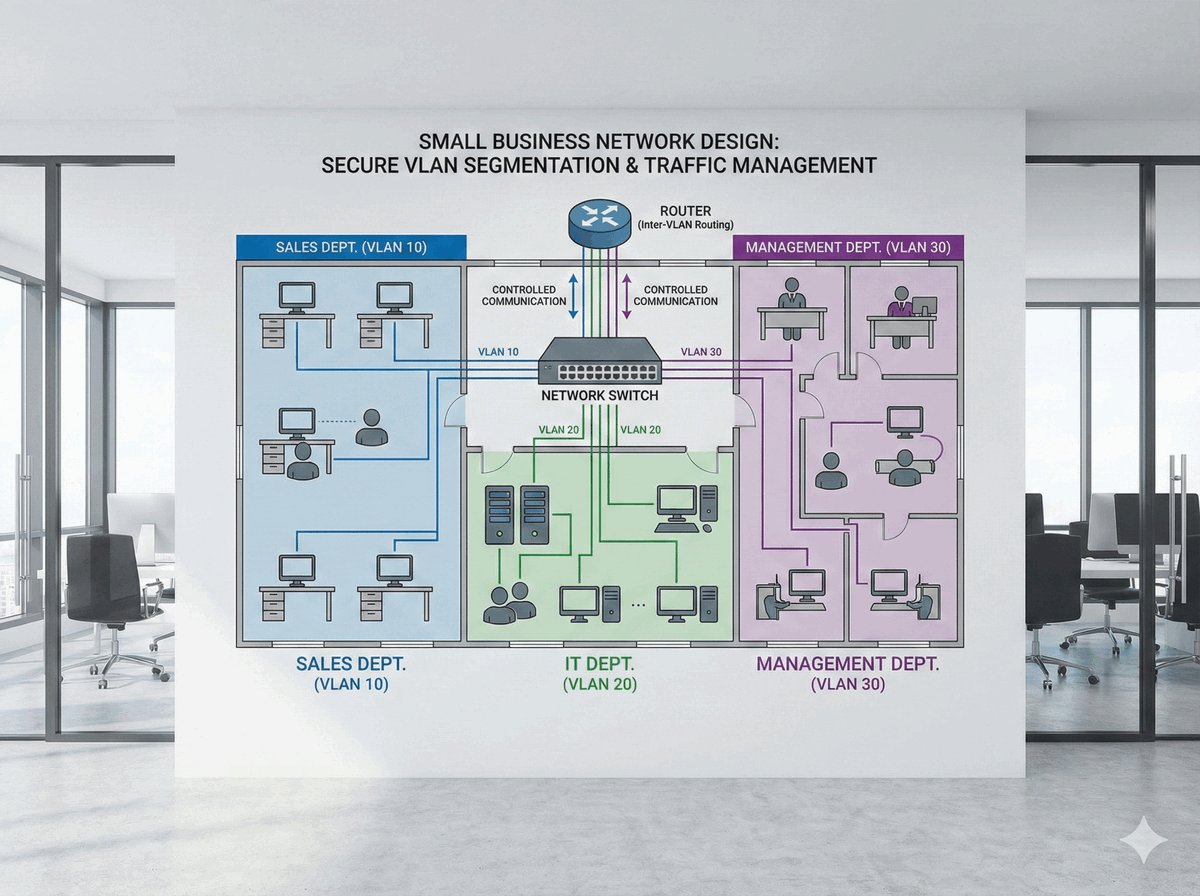
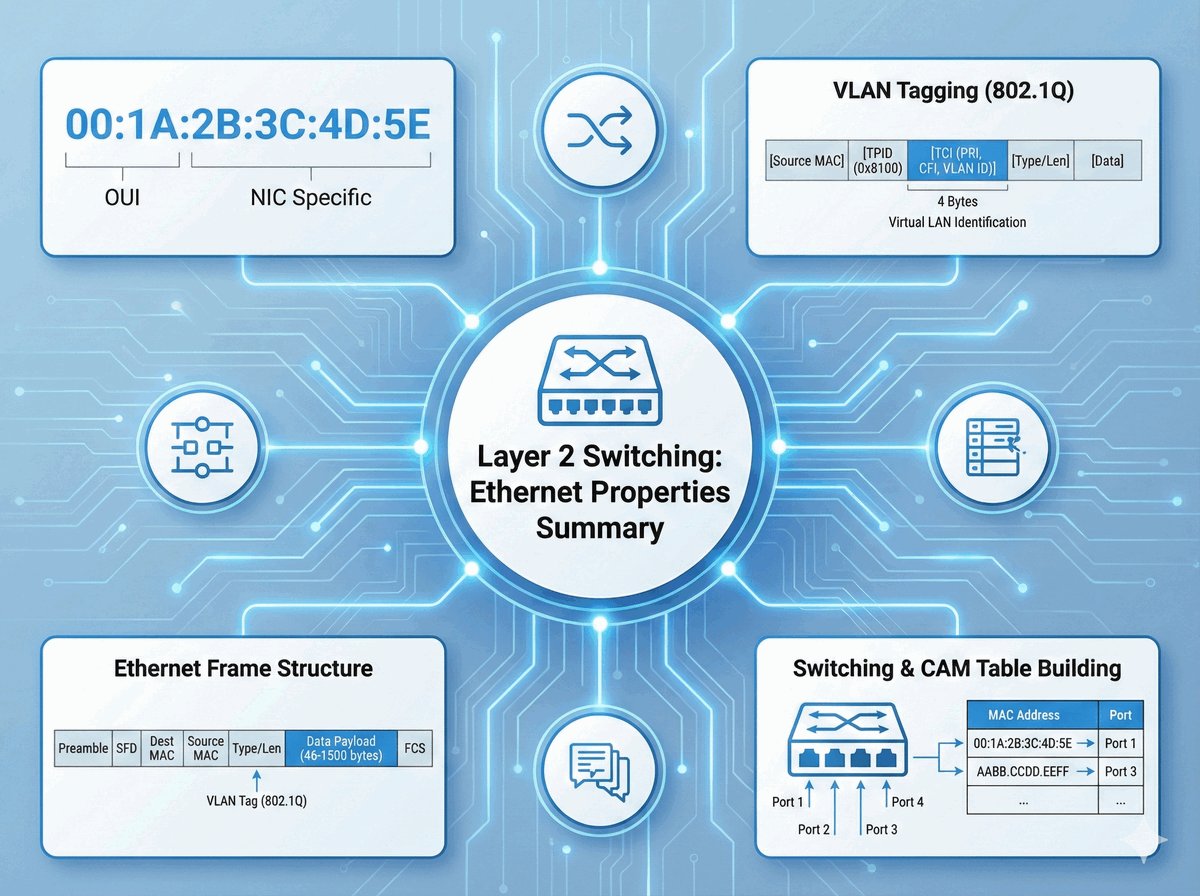
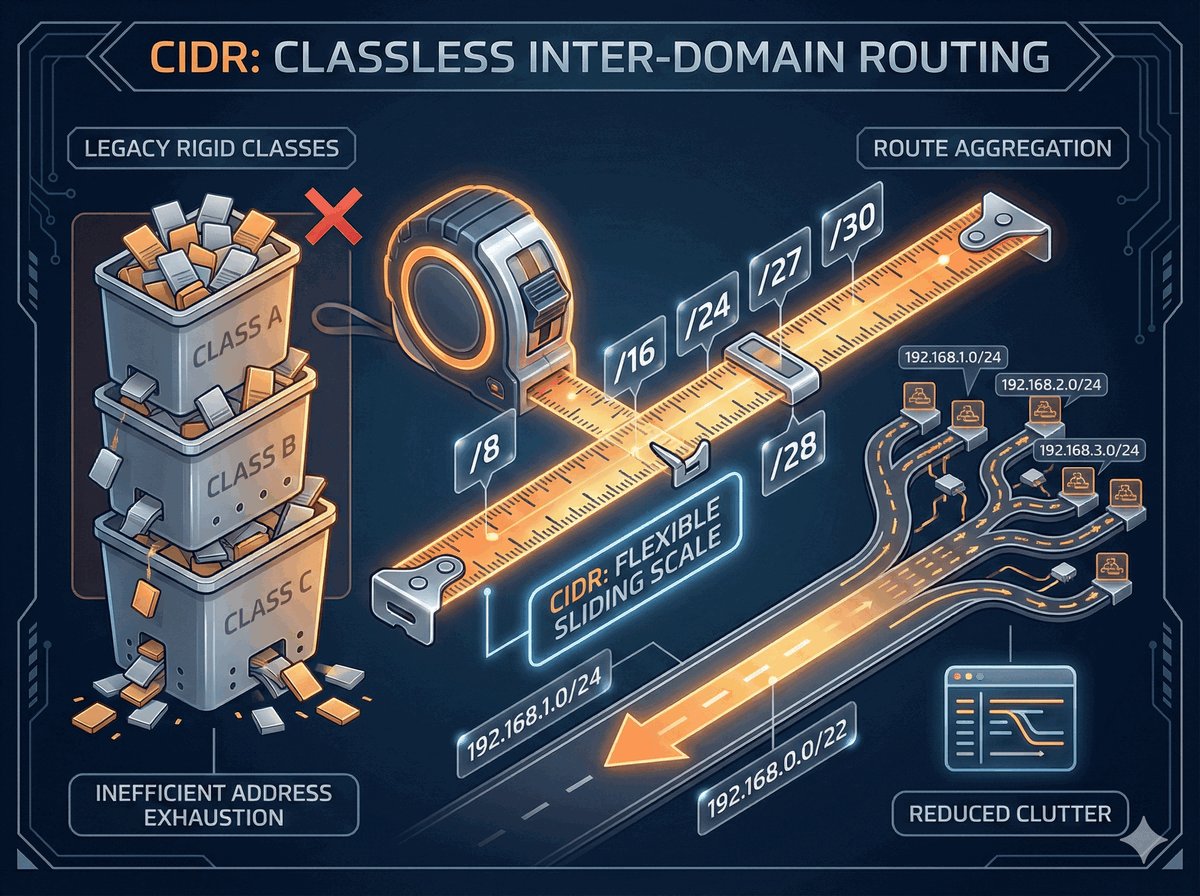
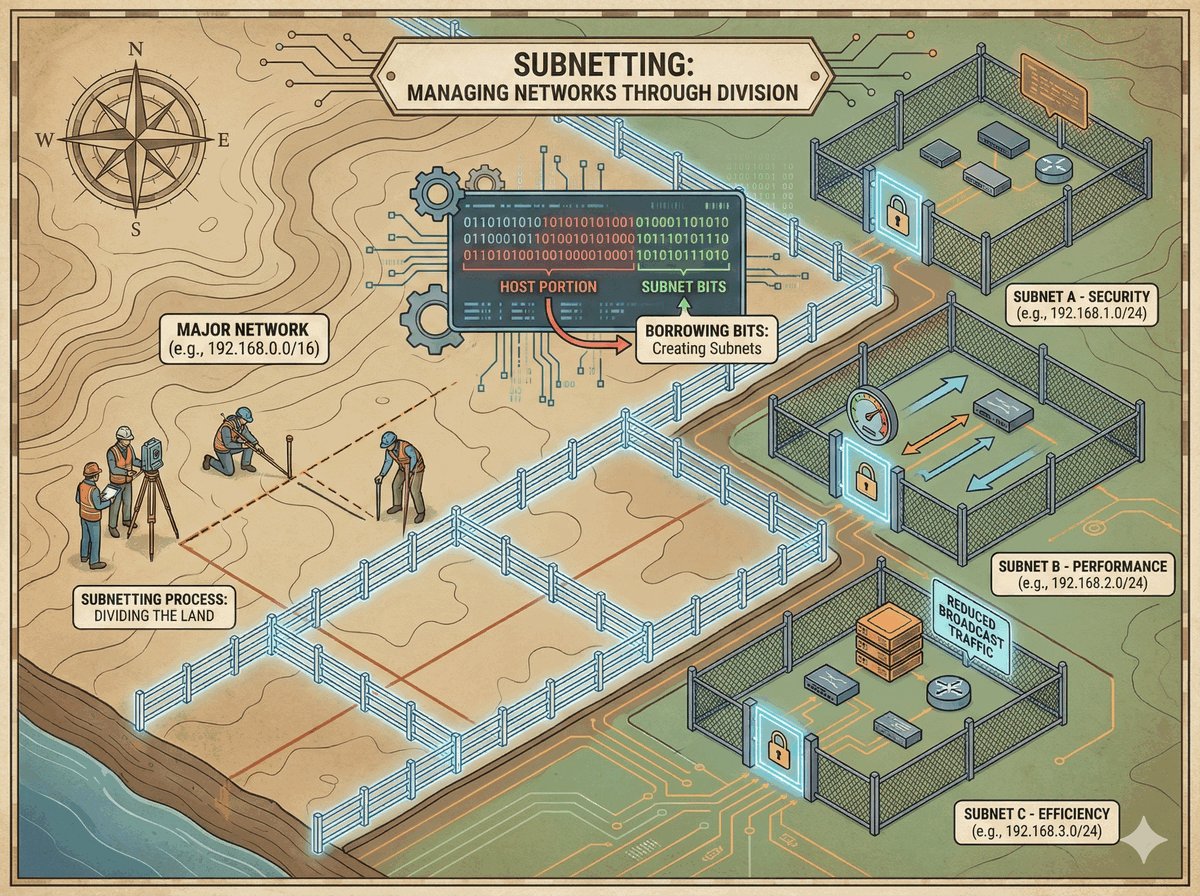
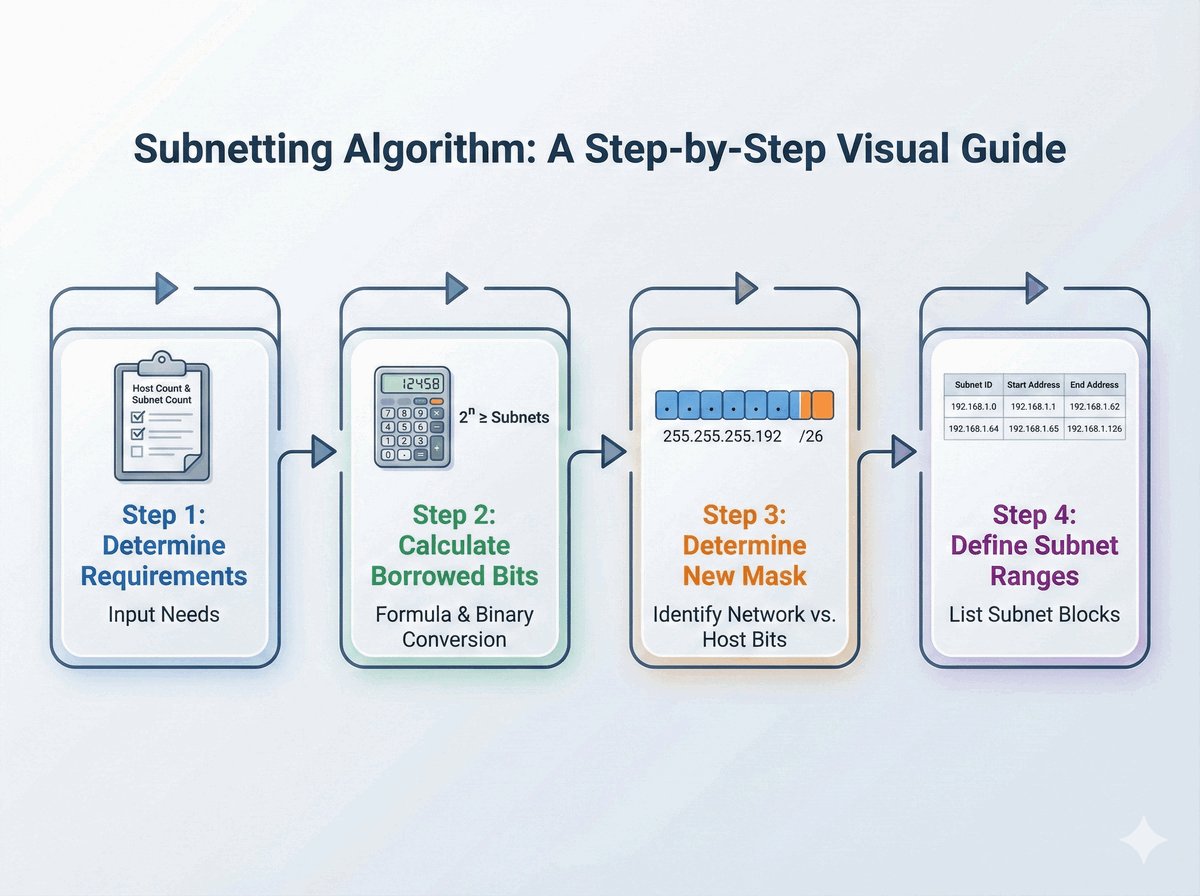
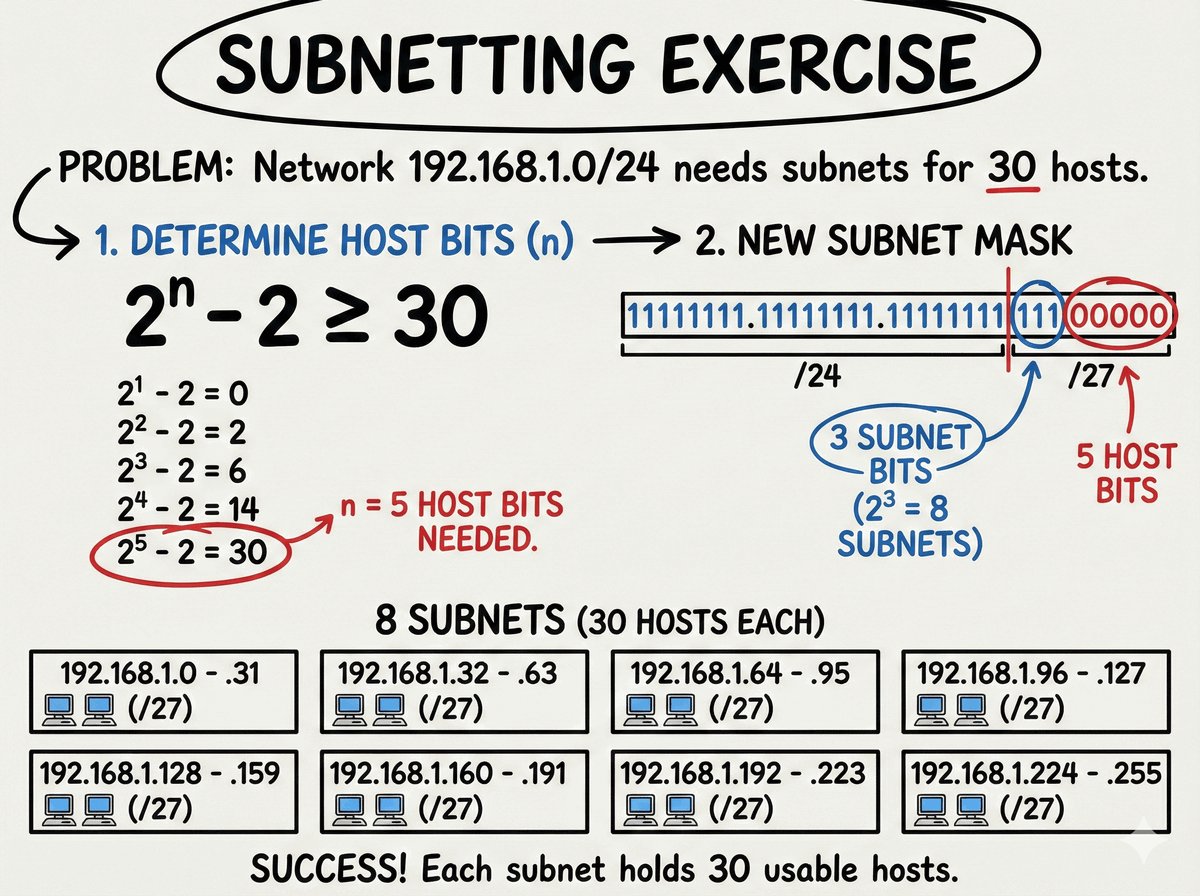
TPID i VID w standardzie 802.1Q
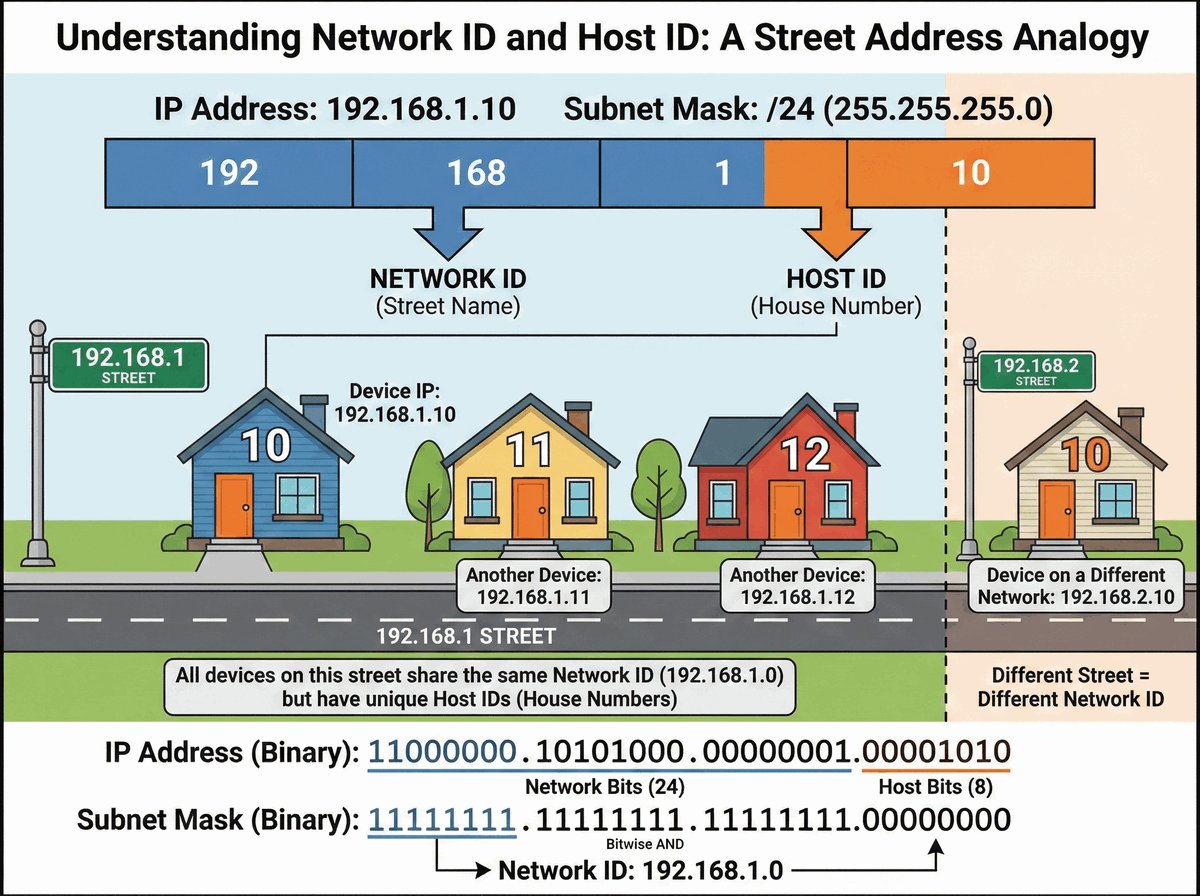
W standardzie 802.1Q kluczową rolę w procesie znakowania ramek odgrywają dwa pola: TPID oraz VID. Pole TPID (Tag Protocol Identifier) to dwubajtowy znacznik o stałej wartości 0x8100. Informuje on urządzenia sieciowe, że dana ramka Ethernet posiada dodatkowy nagłówek i powinna być interpretowana zgodnie z regułami sieci wirtualnych.
Pole VID (VLAN Identifier) to 12-bitowa wartość, która precyzyjnie wskazuje, do której konkretnie sieci wirtualnej (VLAN) przypisana jest ramka. Pozwala to na rozróżnienie aż 4094 unikalnych identyfikatorów. Prawidłowa interpretacja tych pól przez przełączniki jest niezbędna do poprawnego działania mechanizmu trunkingu, czyli przesyłania ruchu z wielu odizolowanych sieci przez jeden wspólny kabel.