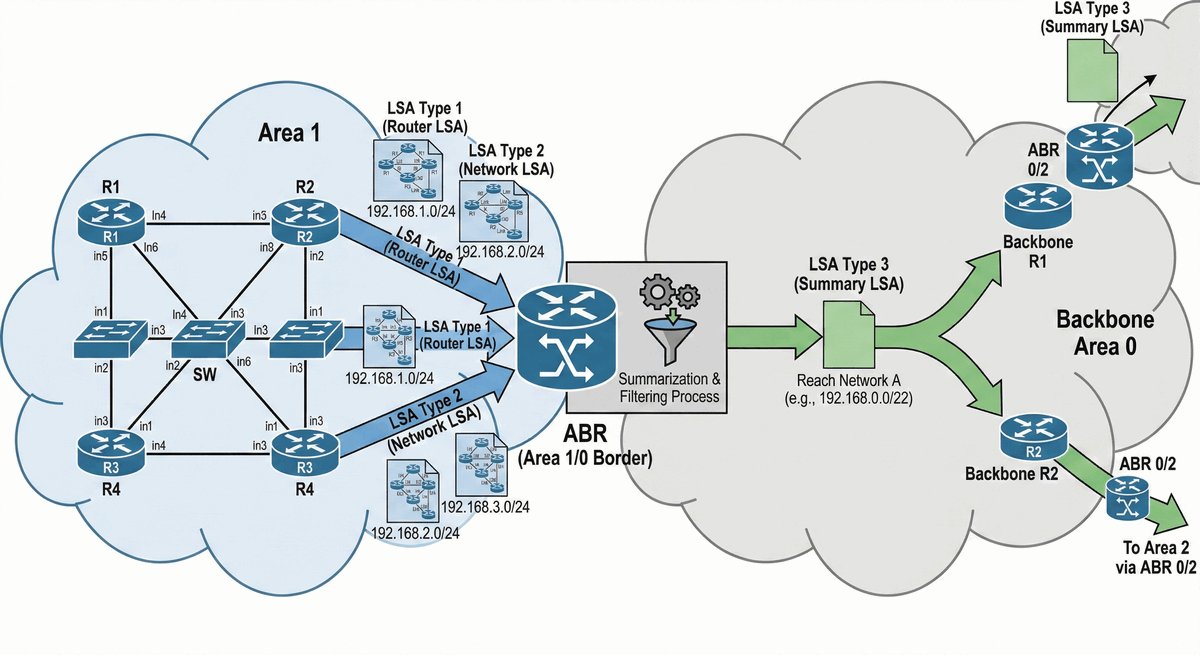
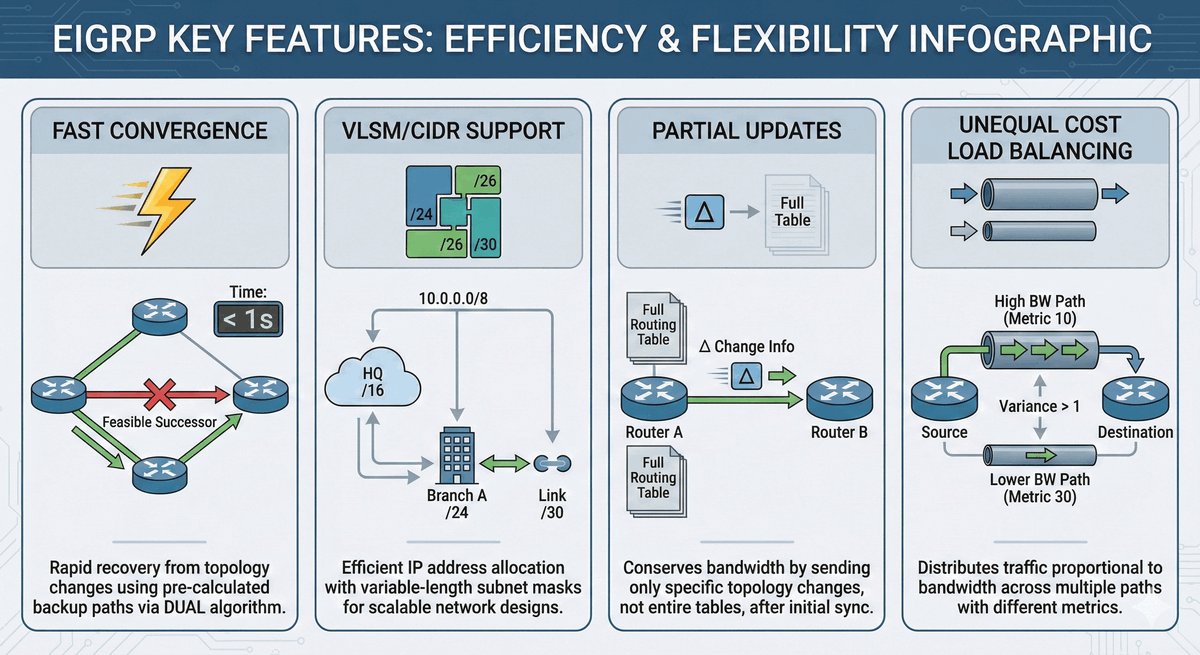
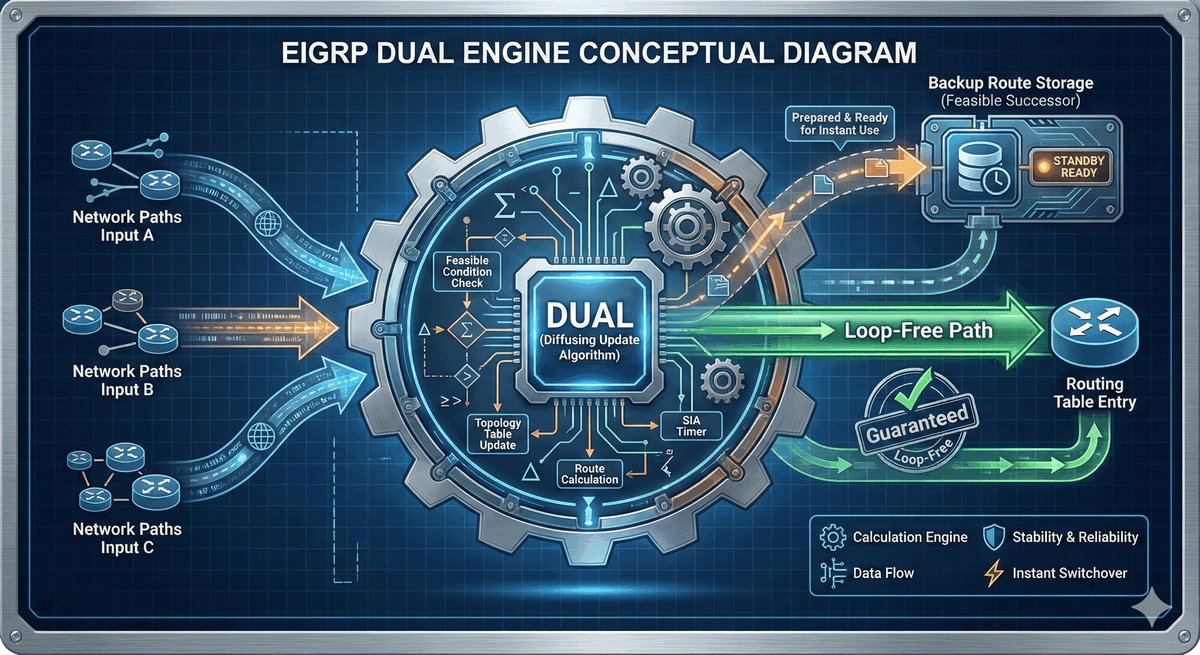
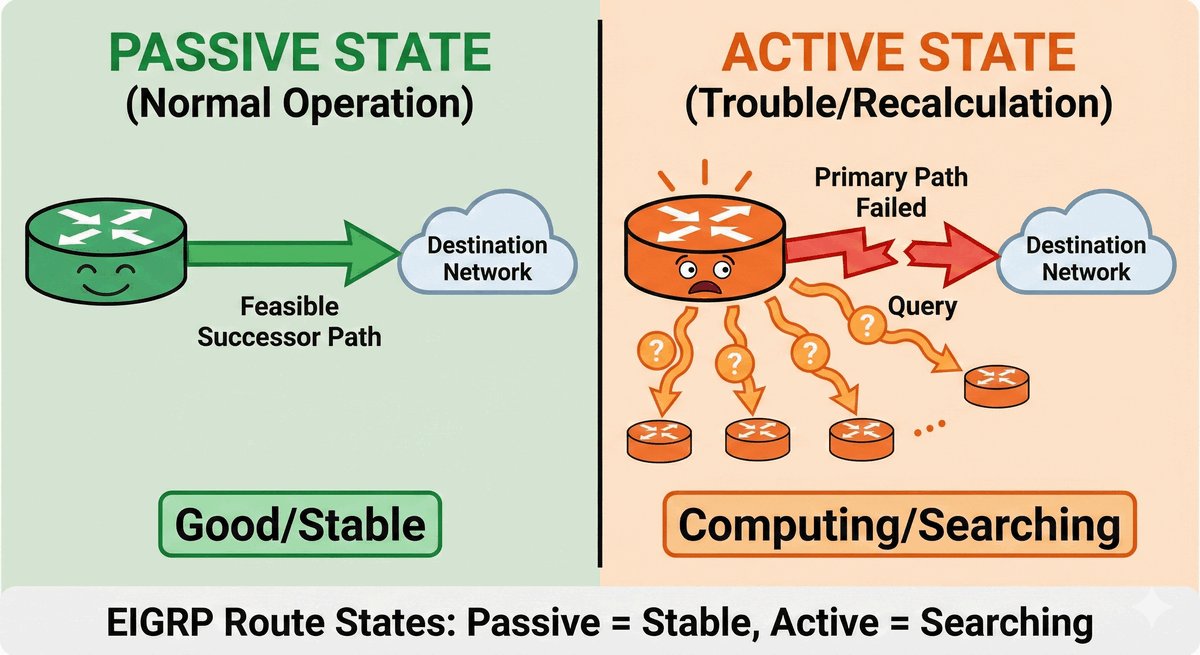
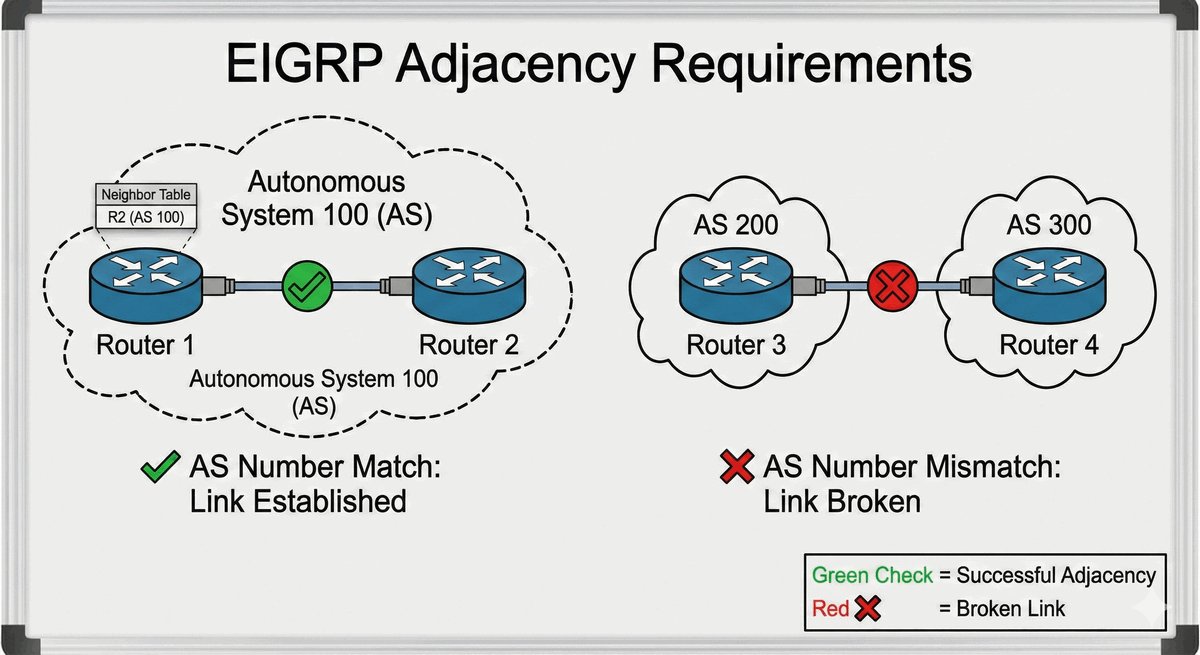
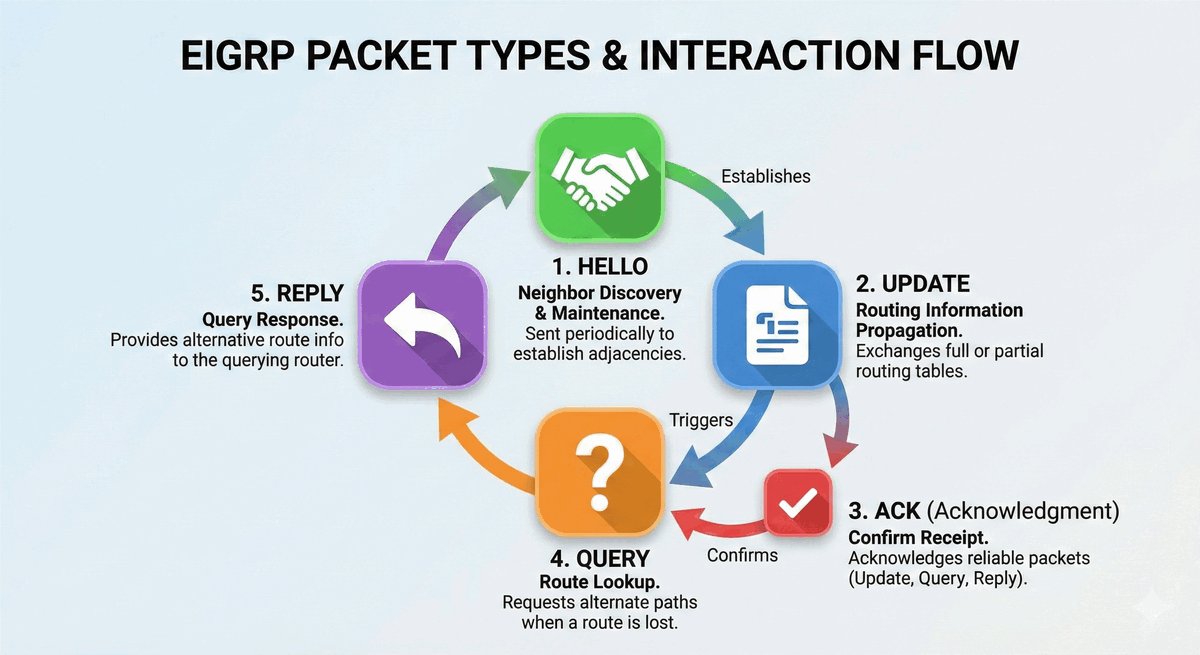
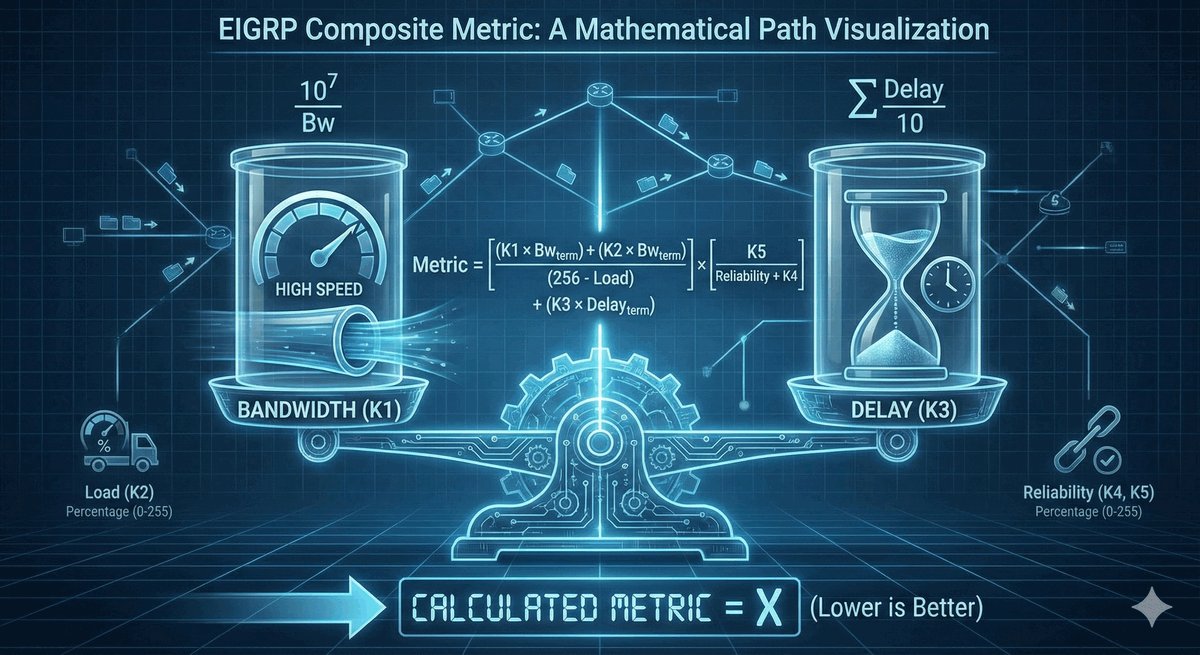
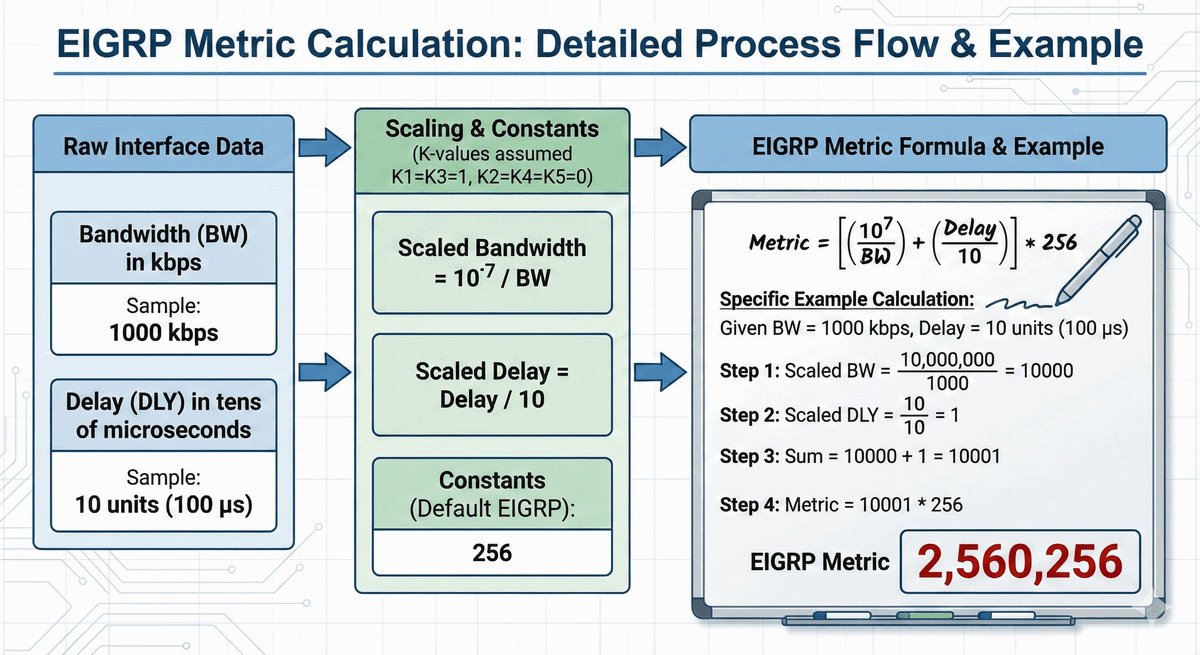
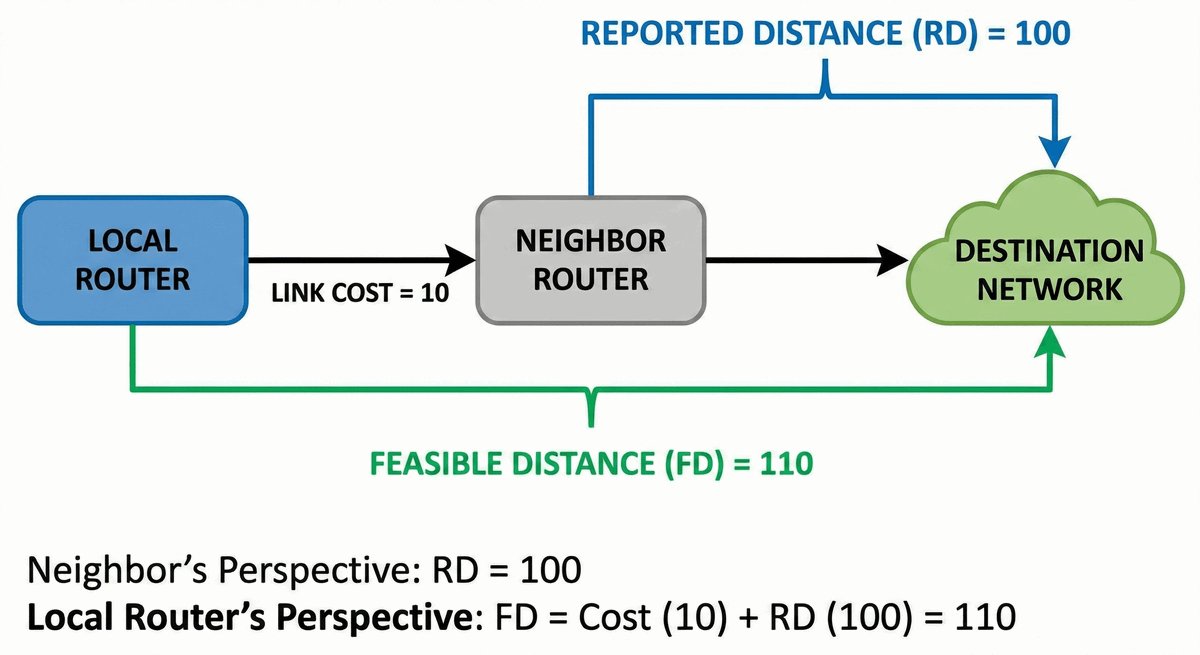
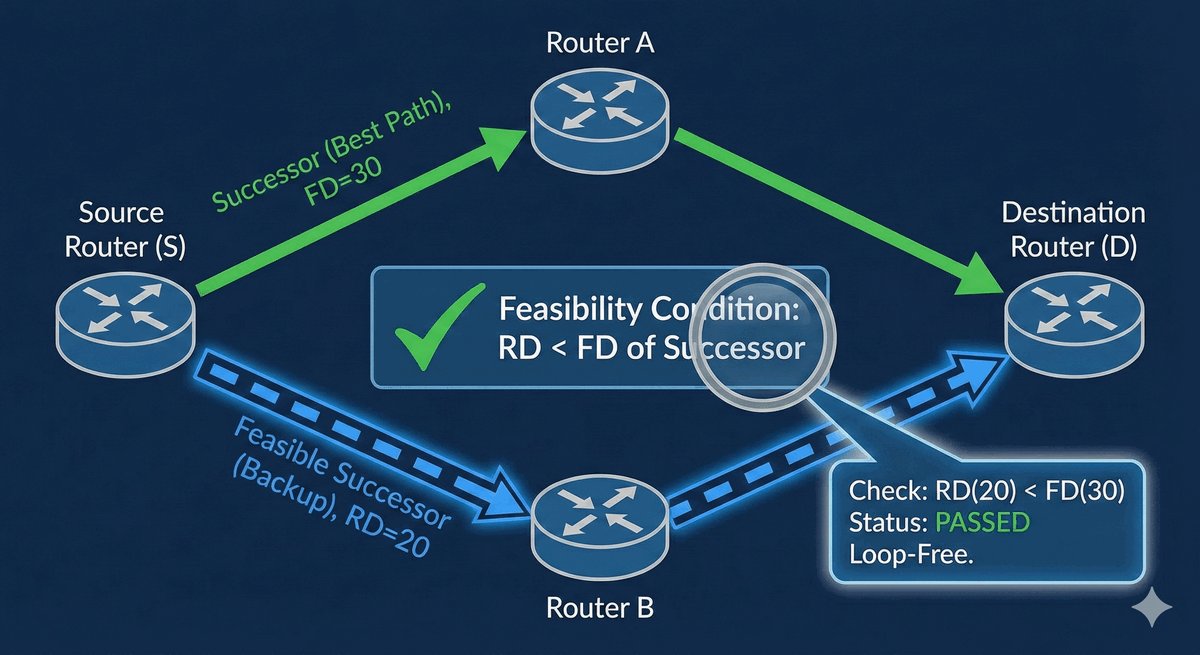
Area Border Router jako strażnik granicy obszarów
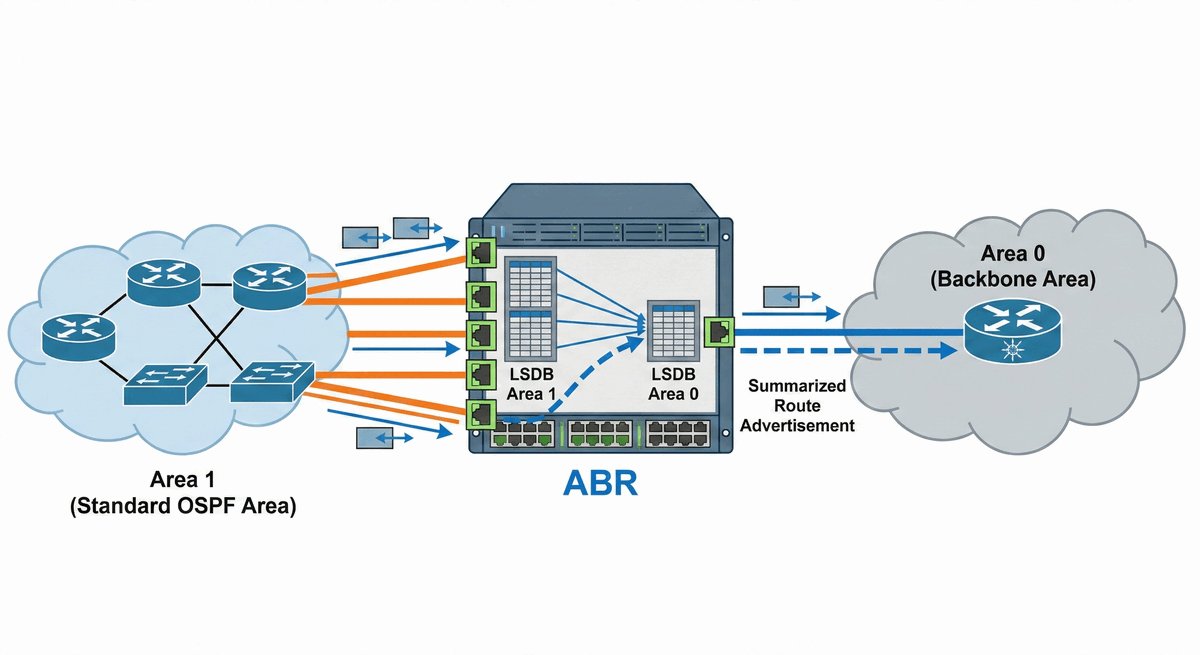
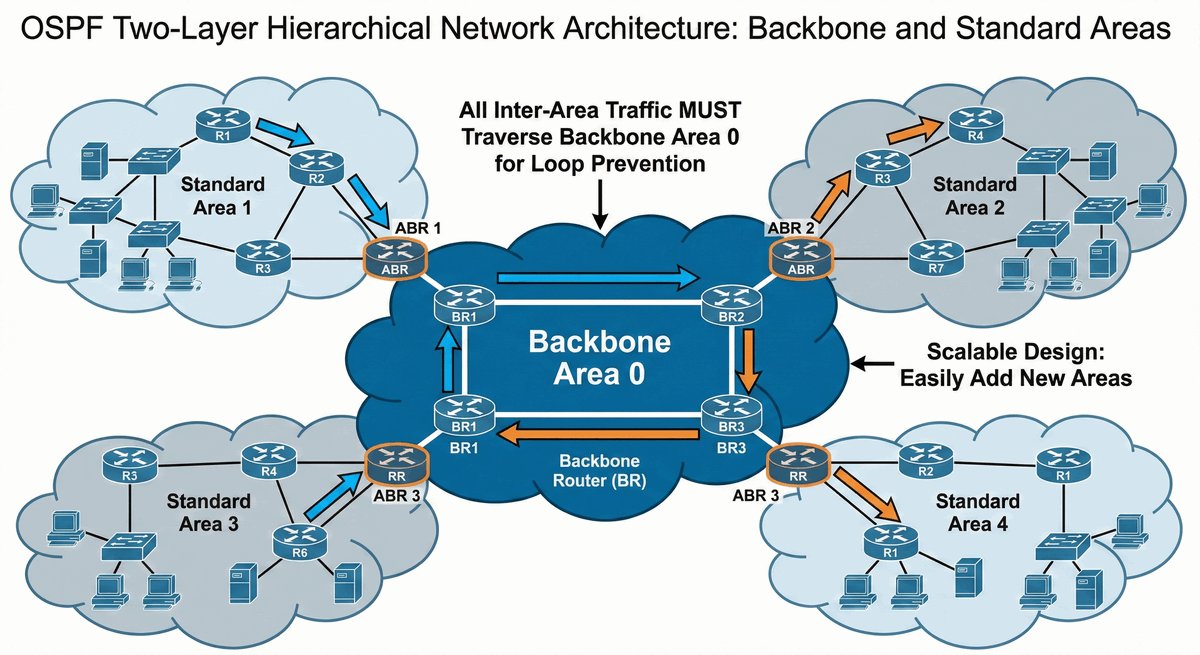
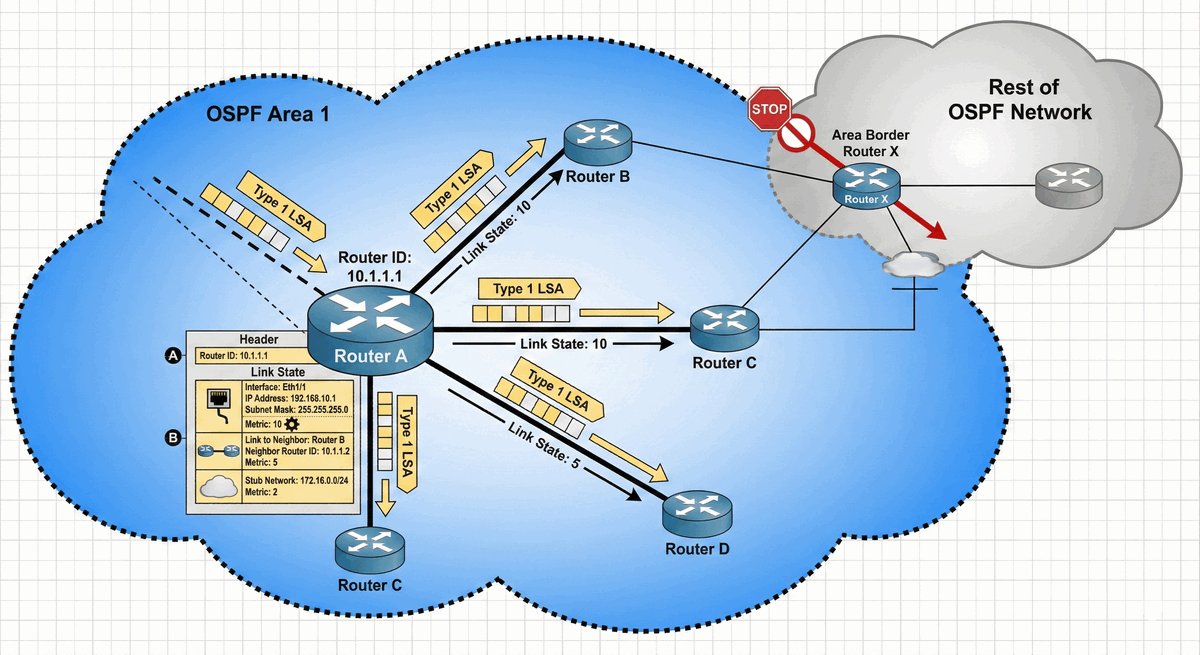
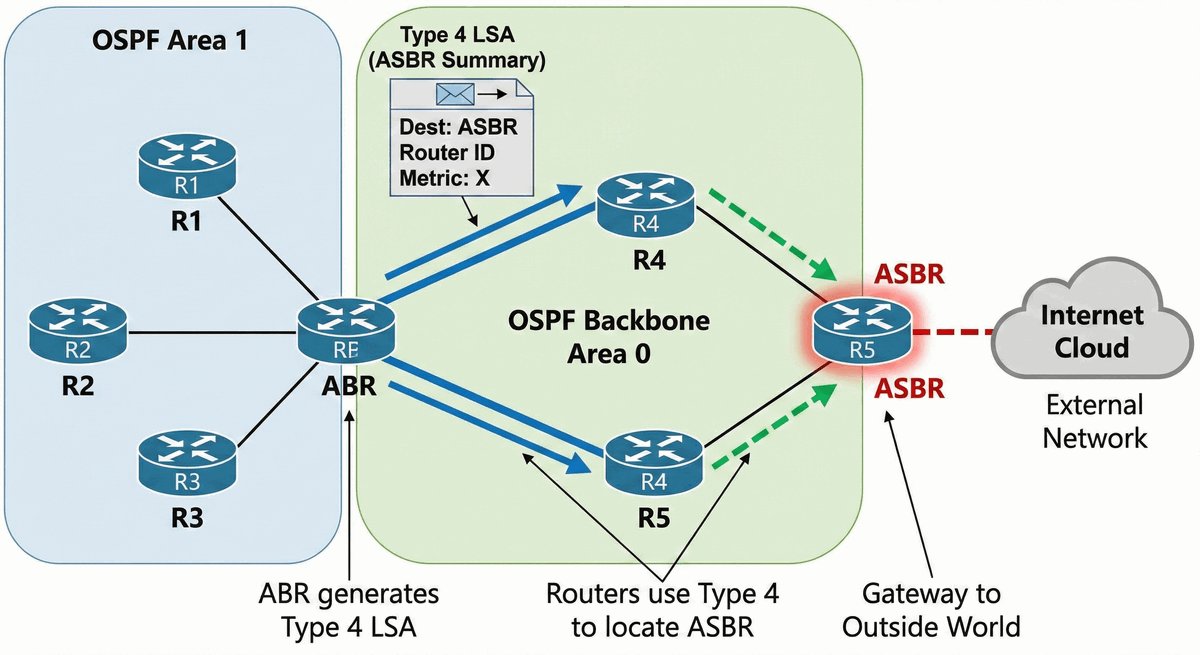
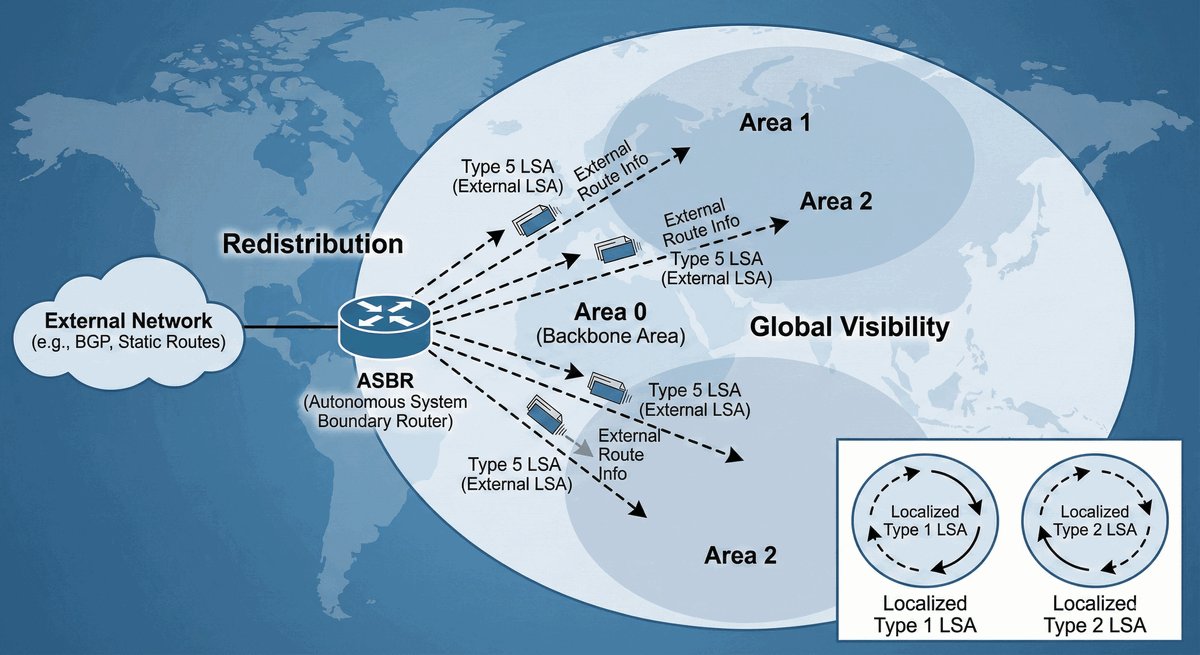
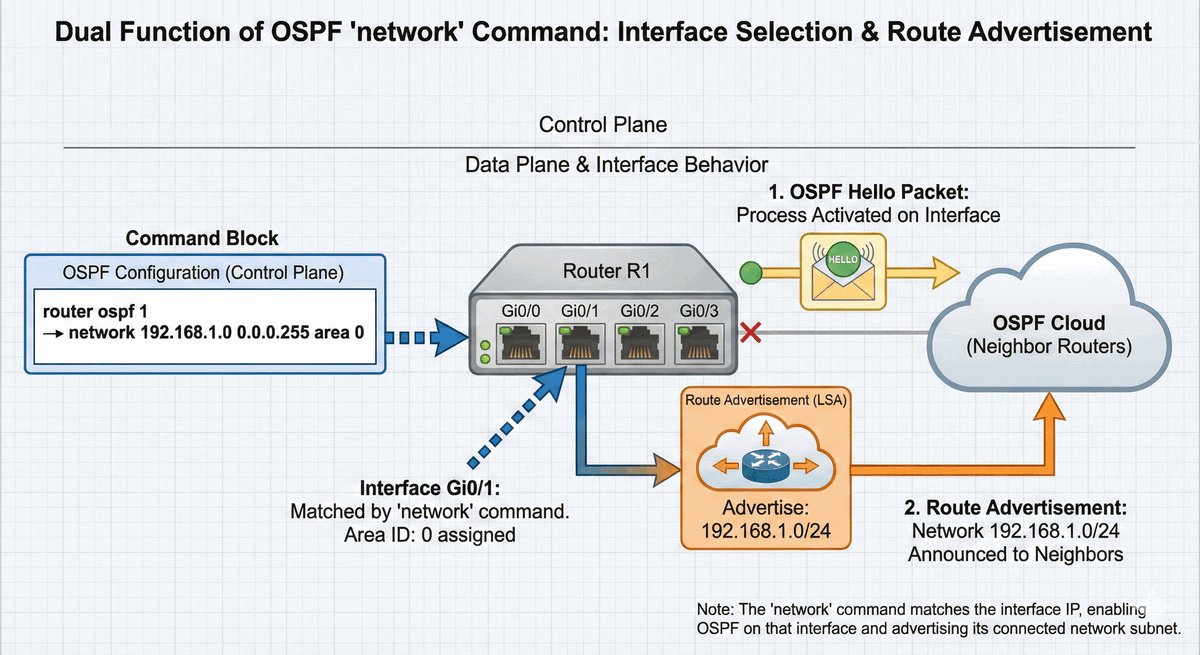
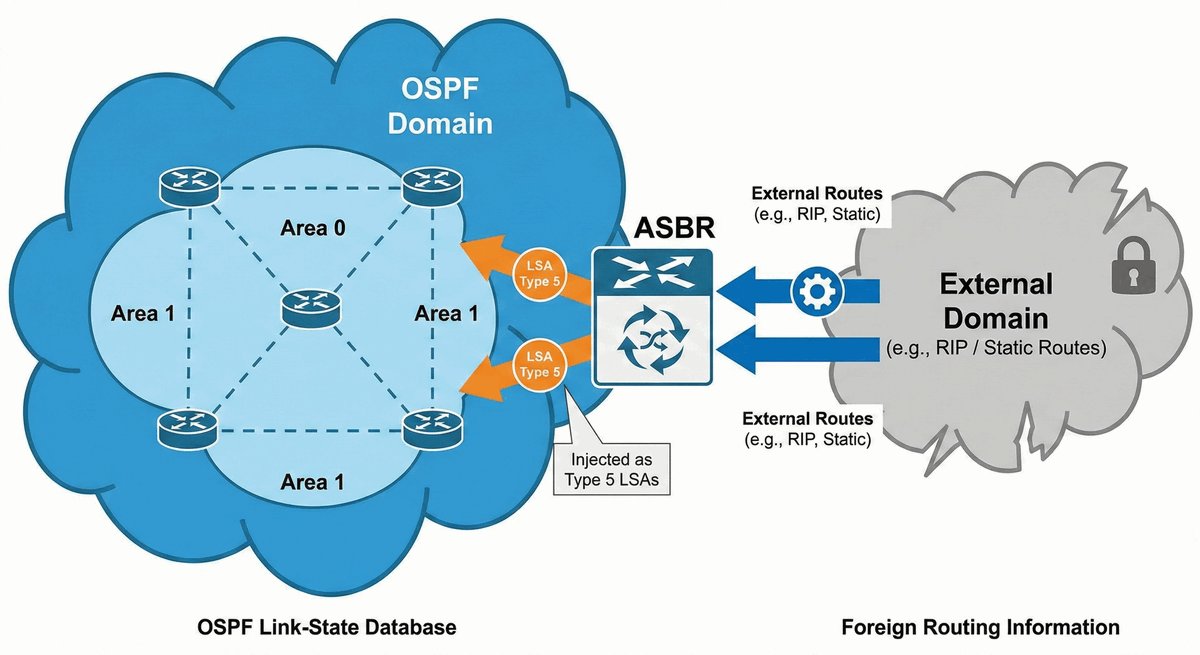
Router ABR (Area Border Router) to kluczowe urządzenie stojące na granicy dwóch światów. Posiada on interfejsy w co najmniej dwóch różnych obszarach OSPF, przy czym jeden z nich musi być "kręgosłupem" sieci (Area 0). To on decyduje, jakie informacje o lokalnych trasach przekazać dalej do reszty firmy.
Jego rola jest podobna do roli tłumacza lub ambasadora — zamiast wysyłać tysiące drobnych szczegółów o każdym kablu, ABR tworzy zgrabne streszczenia (sumaryzację). Dzięki temu routery w odległych oddziałach nie muszą znać topologii całego biura w innym mieście, co oszczędza ich moc obliczeniową i stabilizuje pracę całej infrastruktury.