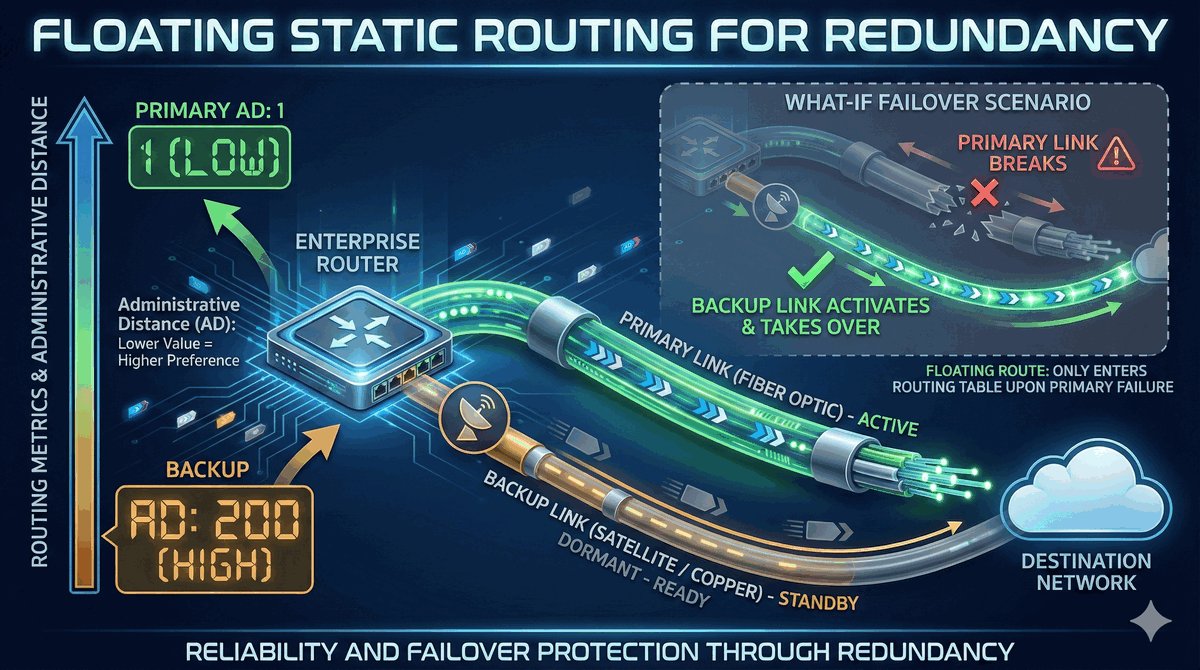
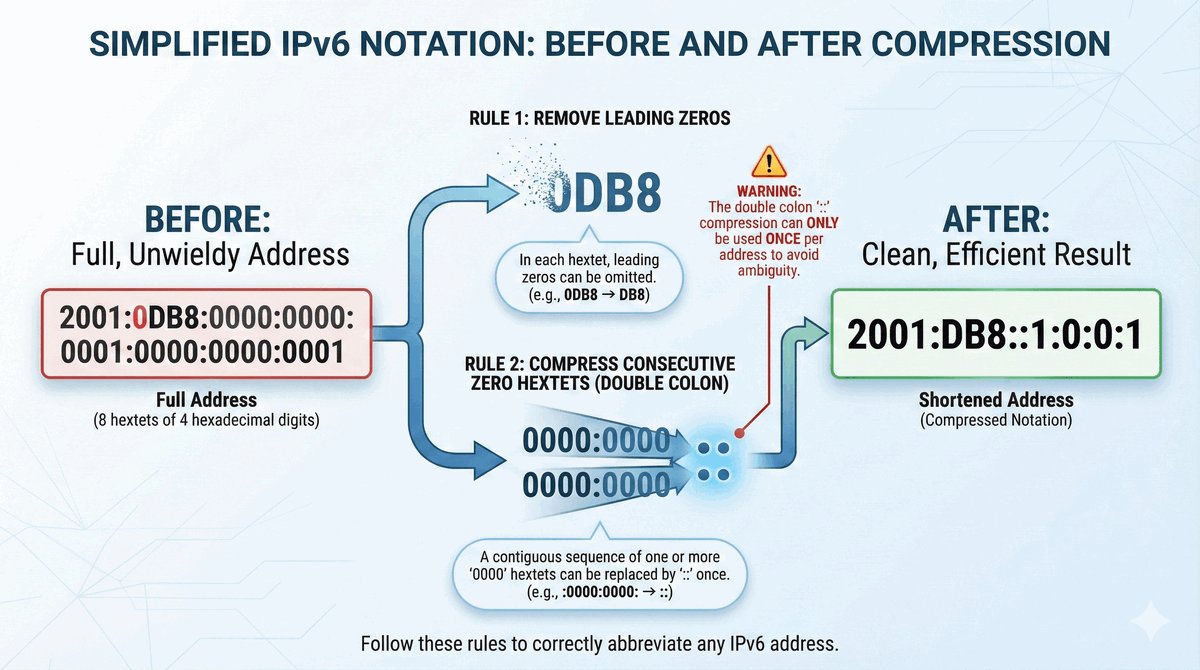
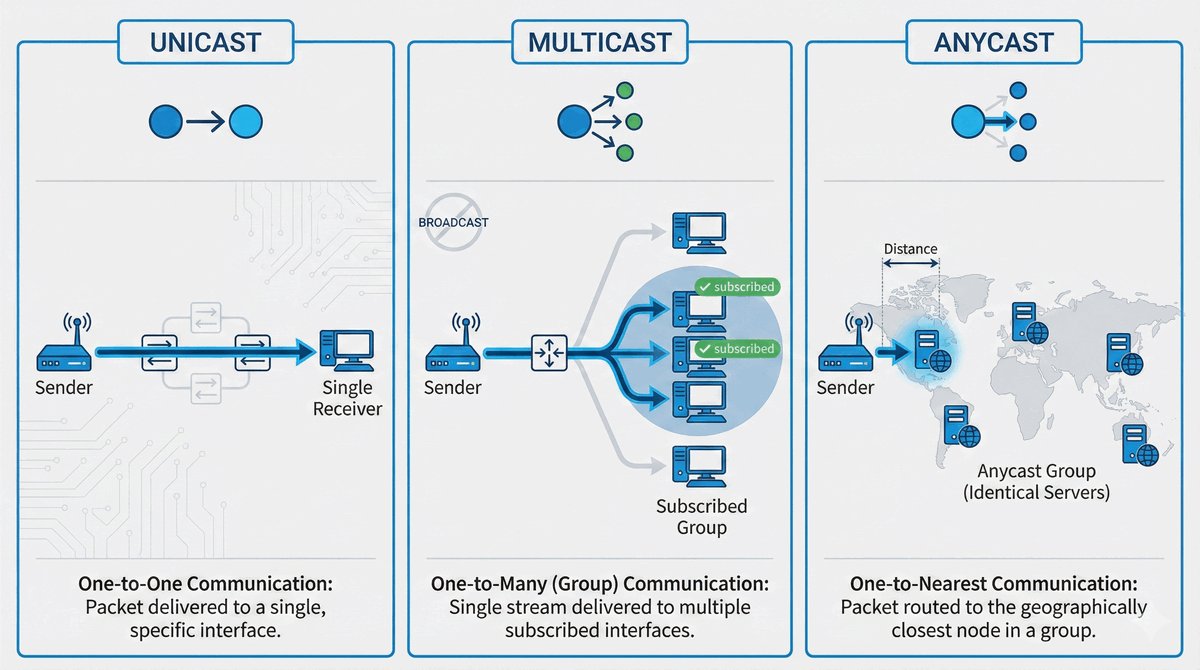
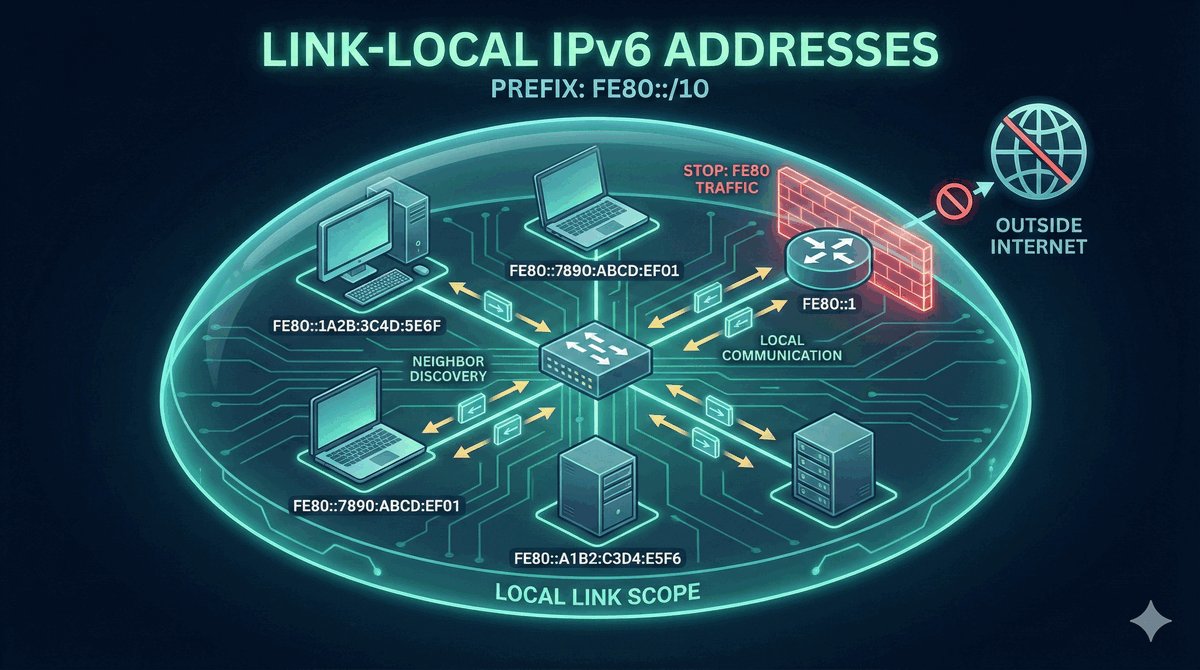
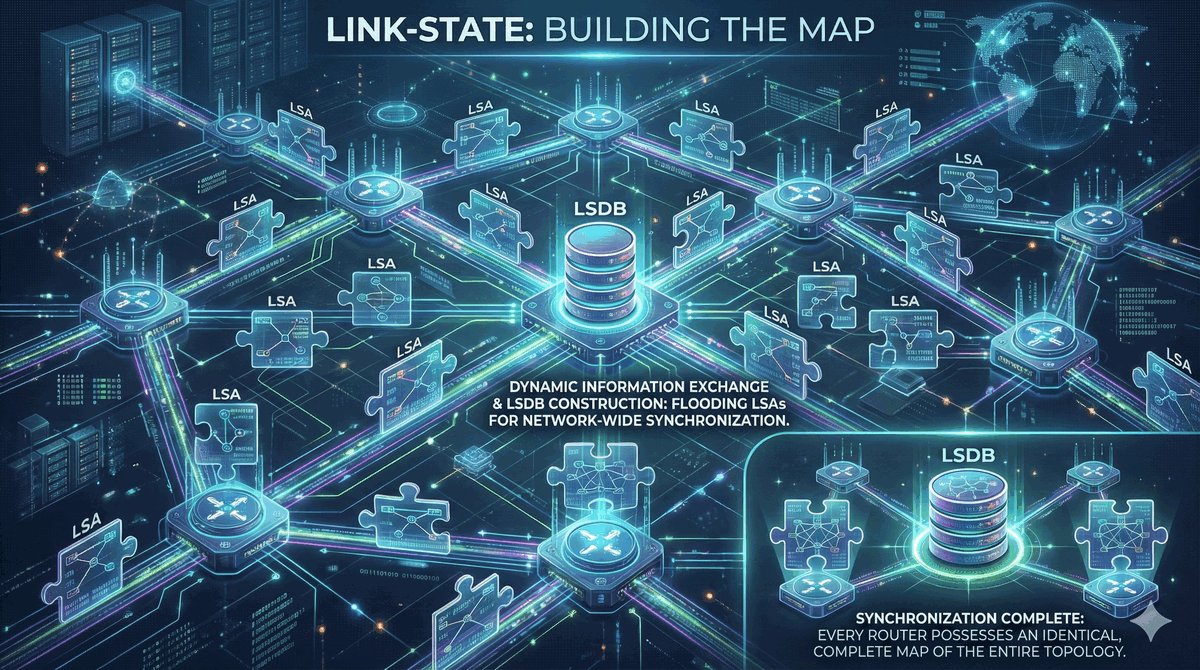
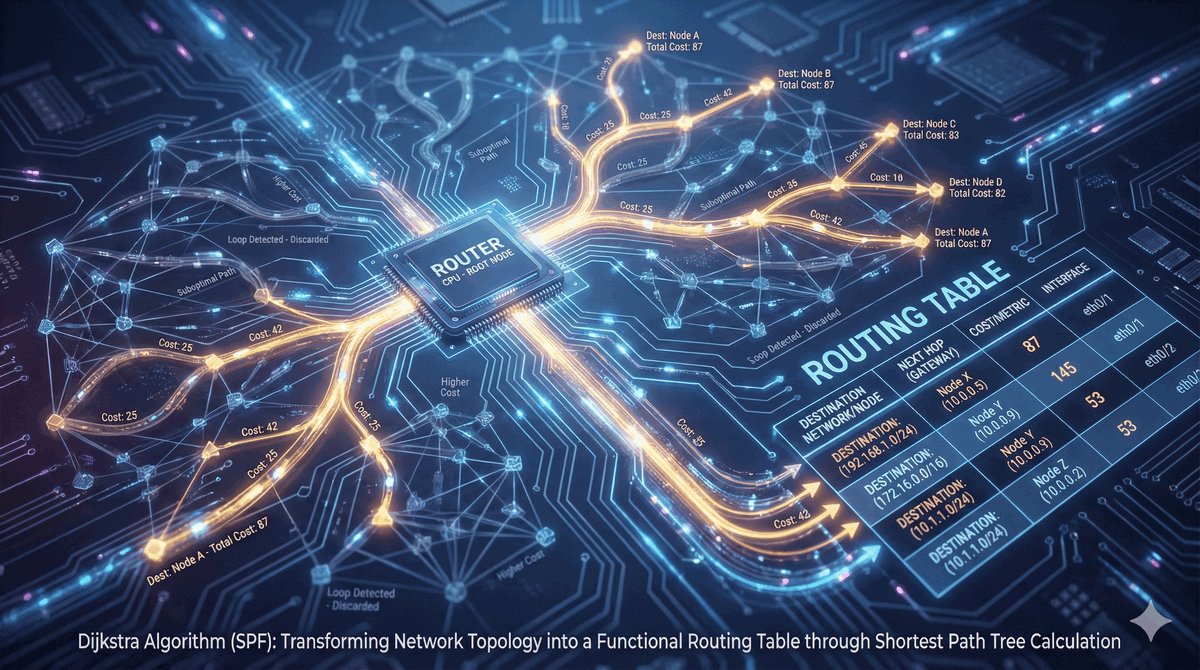
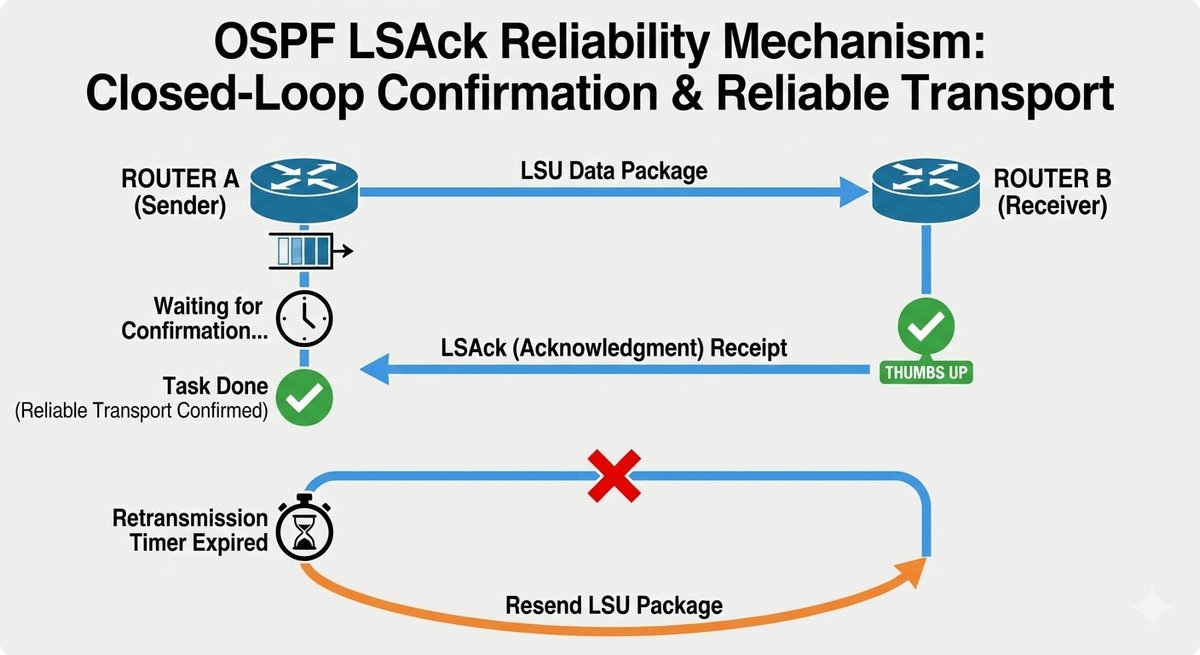
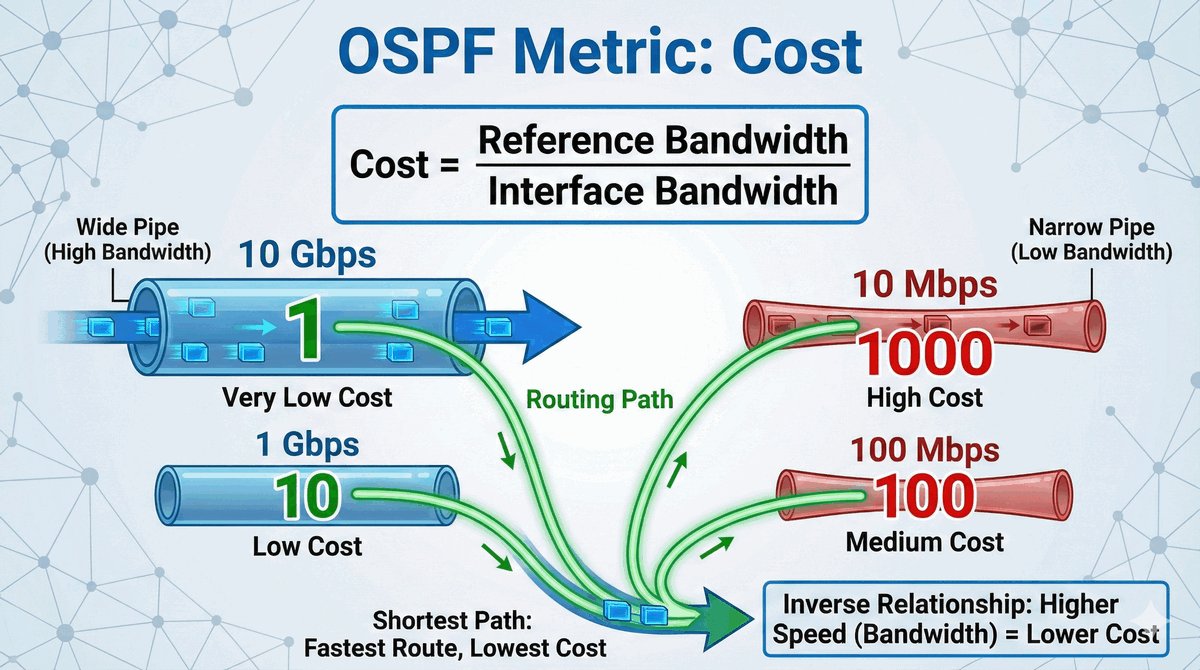
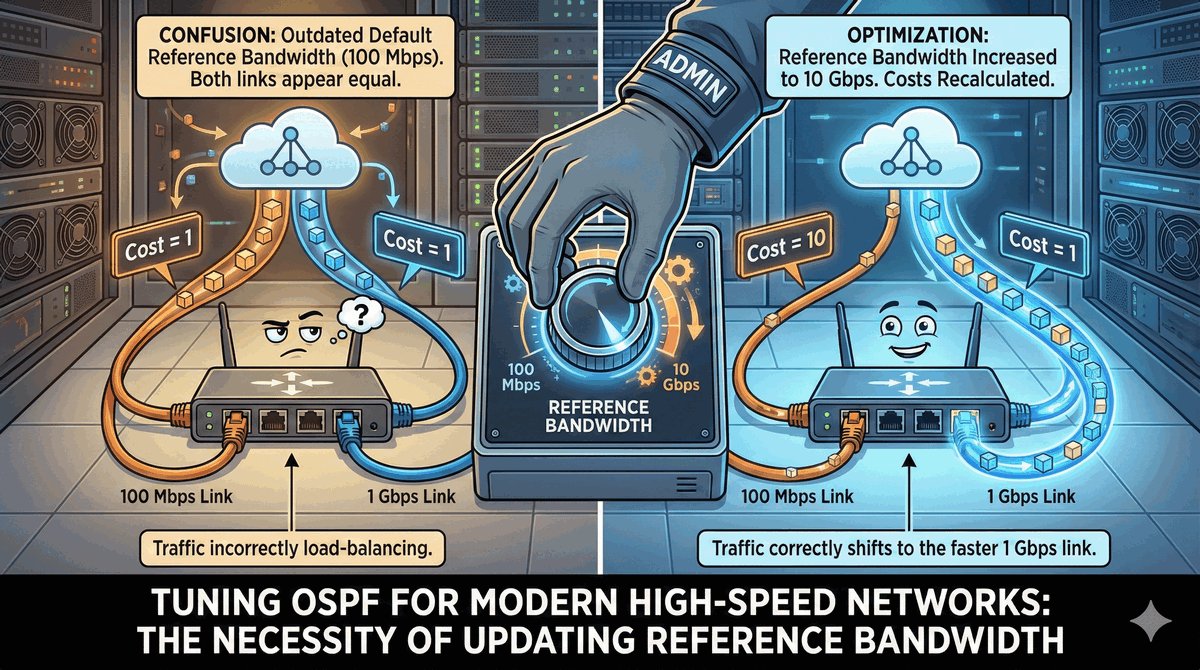
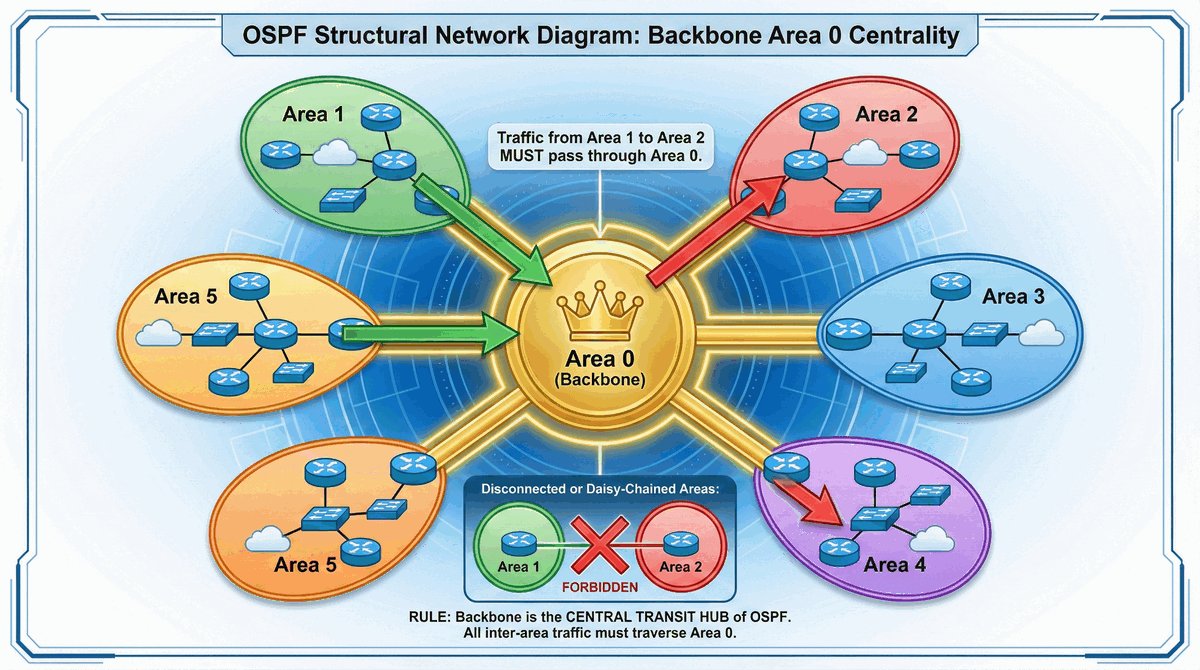
Trasy Connected jako fundament routingu
Najprostszą formą routingu są trasy do sieci, które router "widzi" bezpośrednio na swoich portach. Gdy tylko podłączymy kabel i poprawnie skonfigurujemy adres IP na interfejsie, urządzenie automatycznie dodaje wpis oznaczony literą C (Connected) do swojej tablicy.
Takie połączenia są uznawane za najbardziej wiarygodne, ponieważ router nie potrzebuje pośredników, aby wysłać do nich dane. Ich metryka (czyli koszt dotarcia) wynosi zawsze 0. To fundament, na którym budujemy całą resztę — bez poprawnie działających sieci bezpośrednich żaden inny protokół routingu nie będzie w stanie nawiązać połączenia ze światem.